Statisticsアプリ(統計計算)
入力データに基づいて統計計算を実行し、要約統計量や回帰モデル情報を表示したり、グラフを描いたりするためのアプリです。仮説検定や信頼区間を求める機能も備えています。
Statisticsアプリで実行したいことを選ぶ
-
h > Statisticsを選ぶ。
-
>押す。
-
Setupタブの1行目を反転させ、Oを押す。
-
メニューから、実行したいことを選ぶ。
-
O押す。
Statisticsアプリに入り、List Editor(リストエディター)タブがアクティブになります。
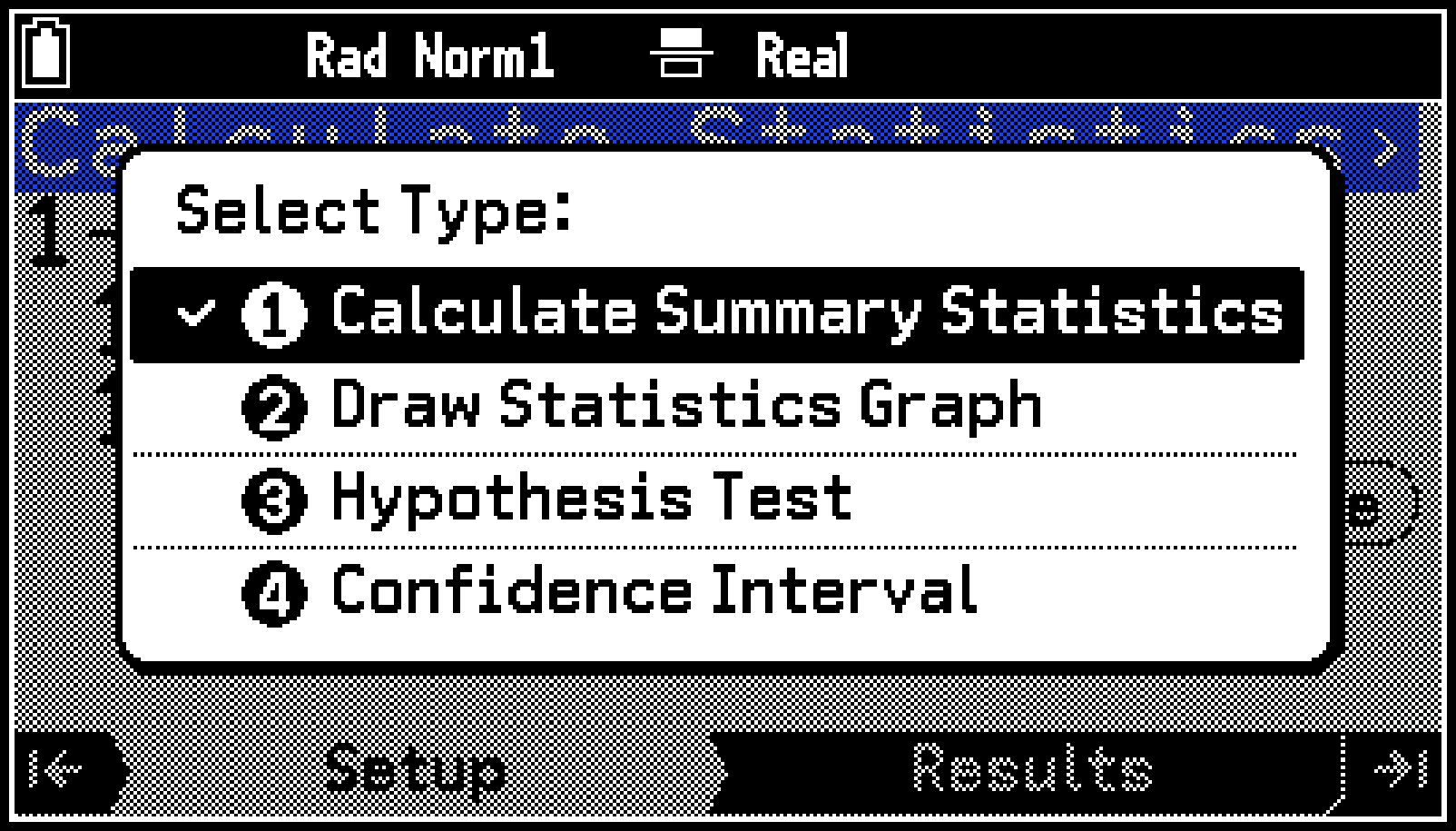
Select Typeメニューが表示されたら手順4へ、表示されなかったら手順3へ進んでください。
|
これをするには: |
このメニュー項目を反転させる: |
|---|---|
|
[Calculate Summary Statistics] |
|
|
統計グラフを描く*2 |
[Draw Statistics Graph] |
|
[Hypothesis Test] |
|
|
[Confidence Interval] |
回帰モデル情報には、回帰式の係数や、決定係数などが含まれます。
2変数データに基づく散布図や回帰グラフ、1変数データに基づくヒストグラムや箱ひげ図などを描くことができます。
Setupタブに、選んだ項目に応じた設定メニューが表示されます。
データを入力する
StatisticsアプリのList Editor(リストエディター)は、統計データを入力・編集するための専用エディターです。List Editorを使って、1度に最大26個のリスト変数(List 1~List 26)を作成できます。
処理対象の統計データに応じて、1つから3つのリスト変数を作成します。*1
|
統計データ: |
作成が必要なリスト変数: |
|---|---|
|
1変数統計データ(度数なし) |
XList*2に割り当てるリスト変数1つ |
|
1変数統計データ(度数付き) |
XListおよびFreq*2に割り当てるリスト変数2つ |
|
2変数統計データ(度数なし) |
XListおよびYList*2に割り当てるリスト変数2つ |
|
2変数統計データ(度数付き) |
XList、YList、Freq*2に割り当てるリスト変数3つ |
仮説検定を実行したり、信頼区間を求めたりする場合は、作成のしかたが異なります。
本機は1変数統計計算に使うリストデータをXList、2変数統計計算に使うリストデータをXListとYList、度数に使うリストデータをFreqまたはFrequencyと表示します。
度数について
統計データの入力方法には、「度数付き」または「度数なし(すべてのデータの度数として1を使用)」の2つの方法があります。List Editorで>を押すと表示されるSetupタブを使って、どちらの方法を使うか指定できます。下記は指定の画面例です。
 |
 |
|
データとしてList1を使用 すべてのデータ値の度数:1 |
データとしてList1を使用 度数としてList2を使用 |
重要!
度数データとして使うリストには、必ず0または正の数だけを入力してください。負数が1つでも入力されたリストを度数データとして使うと、エラー(Out of Domain)となります。
度数が0の統計データは、最大値および最小値の計算には使われません。
List Editorにデータを入力する
下記いずれかの方法で、List Editorにデータを入力します。
各セルに個別に数値を入力する
セルの1つに数値を入力し、Eを押します。
セルに計算式を入力することもできます。この場合、Eを押すと同時に、計算結果の数値が入力されます。
{1,2,3,…}の書式で一括入力する
例: {1,2,3,4,5}を入力する
-
カーソルキーを使ってリスト名を反転させる。
-
C > [Statistics] > [{}]を選び、続いて数値を入力し、Eを押す。

1`2`3`4`5E
他のリスト変数を代入する
List 1のデータをList 2にそのまま代入したり、リスト計算の結果を代入したりできます。
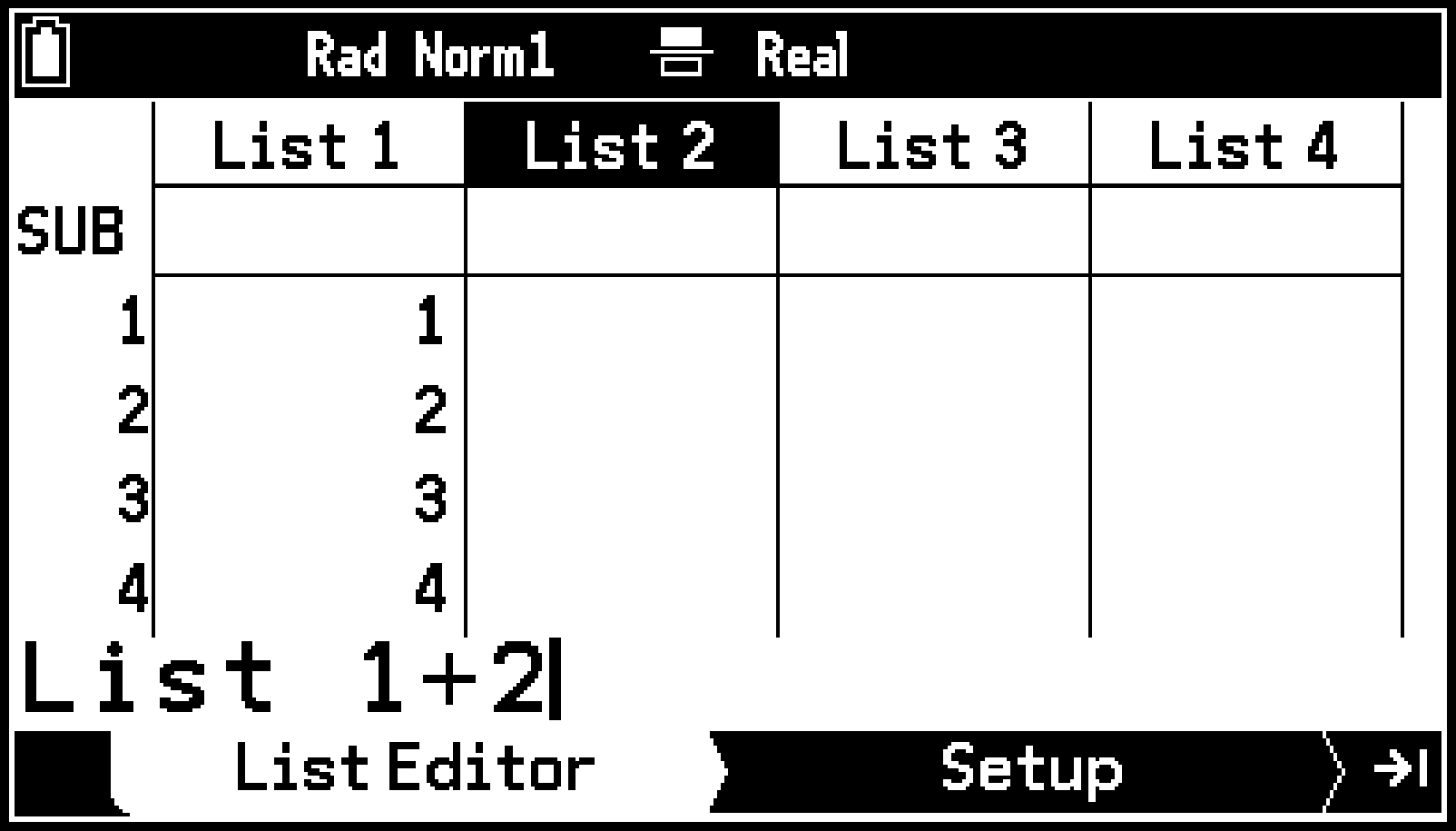
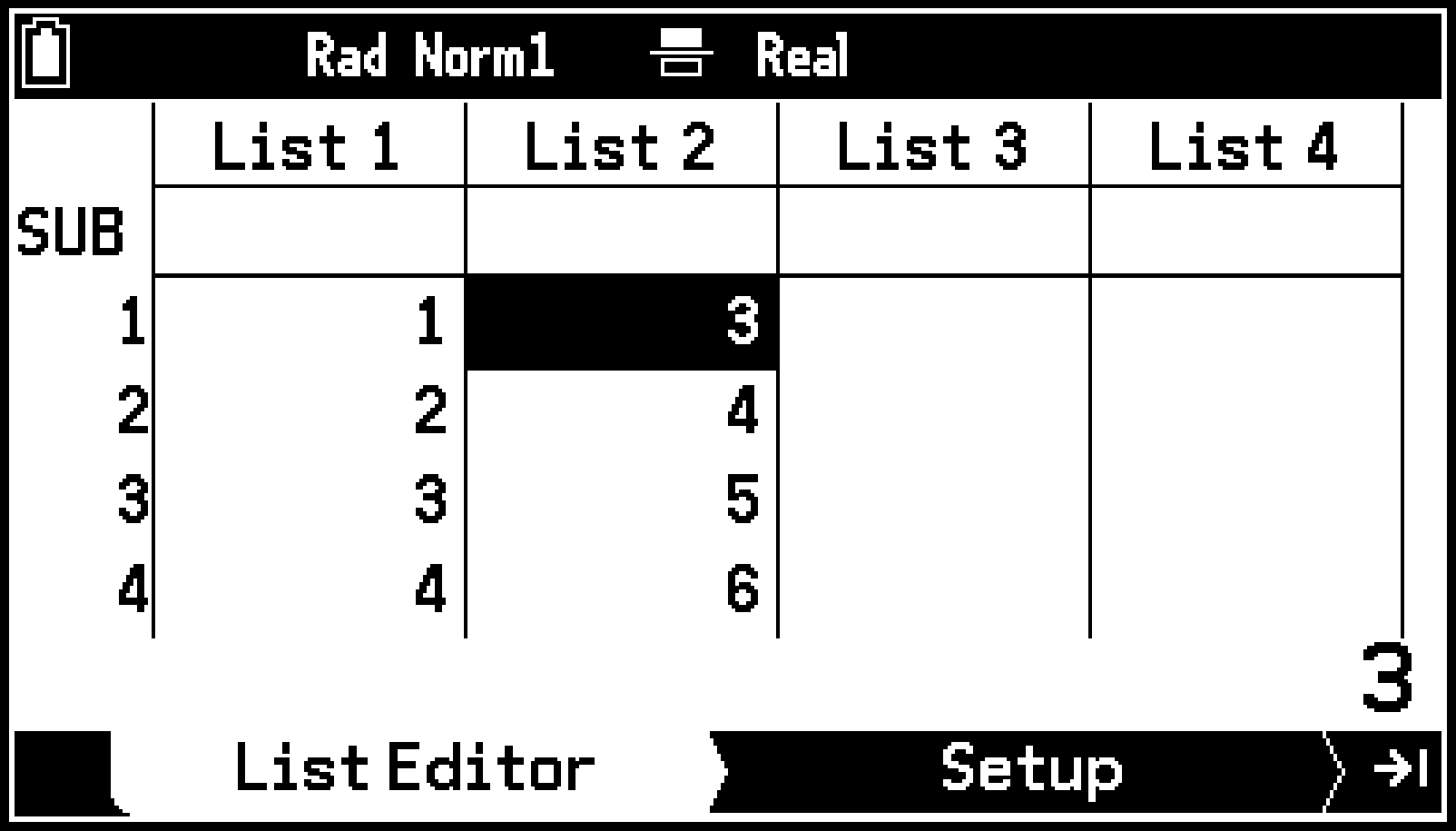
例: List 1+2(List 1の各要素に2を加える)をList 2に代入する
-
カーソルキーを使ってList 2のリスト名を反転させる。
-
“List 1+2”を入力する。
-
Eを押します。
V > [List] > [List 1]+2
参考
Calculateアプリを使ってリスト変数を操作することもできます。リスト変数を保存するを参照してください。
List Editorタブを使う
セルの内容を編集するには
|
これをするには: |
このように操作する: |
|---|---|
|
セルの値を変更する |
対象のセルを反転させ、新しい数値を入力する。 |
|
セルの内容を編集する |
対象のセルを反転させ、T > [Edit]を選ぶ。 |
|
セルの内容を削除する |
対象のセルを反転させ、T > [Delete] > [One Value]を選ぶ。 削除したセル以降のすべての行が1行上に移動します。 |
|
あるリスト内の全セルの内容を削除する |
全セルの内容を削除したいリスト内のセルいずれか1つを反転させ、T > [Delete] > [One List]を選ぶ。 |
|
List Editorタブの全リストを削除する |
T > [Delete] > [All Lists]を選ぶ。 |
|
新しいセルを挿入する |
T > [Insert]を選ぶ。 “0”が入力された新しいセルが挿入され、そのセル以降のすべての行が1行下に移動します。 |
リストにサブネームを付けるには
サブネームを付けたいリストの“SUB”行を反転させ、名前を入力します。8文字まで入力できます(ただし表示されるのは、幅に収まる範囲の文字となります)。
“SUB”行は、S > [Sub Name]がオフのときは表示されません。
値の表示色を変更するには
|
これをするには: |
このように操作する: |
|---|---|
|
1つのセルの表示色を変更する |
|
|
1つのリスト内すべての値の表示色を変更する* |
|
この操作でサブネームの表示色は変わりません。またこの操作後に、未入力のセルに入力した値の表示色は、黒(初期設定)となります。
リストの要素を並べ替えるには
List Editorタブのリストの要素を、値の昇順または降順に並べ替えます。並べ替えは、1つのリスト内の値を基準に実行されます。最大6つのリストを並べ替えの対象として指定できます。
-
T > [Sort/Jump] > [Sort Ascending](昇順に並べ替え)または[Sort Descending](降順に並べ替え)を選ぶ。
-
並べ替えるリストの数を入力し、Oを押す。
-
並べ替えの基準となるリストの番号を入力し、Oを押す。
-
ダイアログが表示された場合は、同時に並べ替えるリストの番号を順次指定する。
並べ替えるリストの数を指定するダイアログが表示されます。
並べ替えの基準となるリストを指定するダイアログが表示されます。
手順2で指定したリスト数が1の場合は、ここで入力した番号のリストデータが並べ替えられます。
手順2で指定したリスト数が2以上の場合は、同時に並べ替える2つ目のリストを指定するダイアログが表示されます。
同じリストを2回以上指定すると、エラーとなります。また、要素数(行数)が異なるリストを指定して並べ替えを実行しようとした場合も、エラーとなります。
リストファイルについて
本機は26個のリスト変数(List 1~List 26)を保持する6個のリストファイル(File 1~File 6)を備えており、最大156個のリスト変数をメモリーに保存できます。ただし1度に扱うことができるリスト変数は、現在開いているリストファイルに含まれる26個です。リストファイルを切り替えるには、S > [List File]を選びます。
CSVファイルの読み込みと書き出し
現在開いているリストファイルをCSVファイルに書き出したり、CSVファイルの内容をリストファイルに読み込んだりできます。詳しくはCSVファイルの利用を参照してください
要約統計量や回帰モデル情報を一覧表示する
1変数または2変数の統計データから各種の要約統計量を求め、一覧表示します。また、2変数の統計データに回帰モデルを適用したときの、回帰式の係数や決定係数などの情報(本書では「回帰モデル情報」と呼びます)を一覧表示します。
操作の流れ
-
計算に使う統計データを入力する。
-
Statisticsアプリで実行したいことを選ぶに従って操作し、[Calculate Summary Statistics](要約統計量の計算)を選ぶ。
-
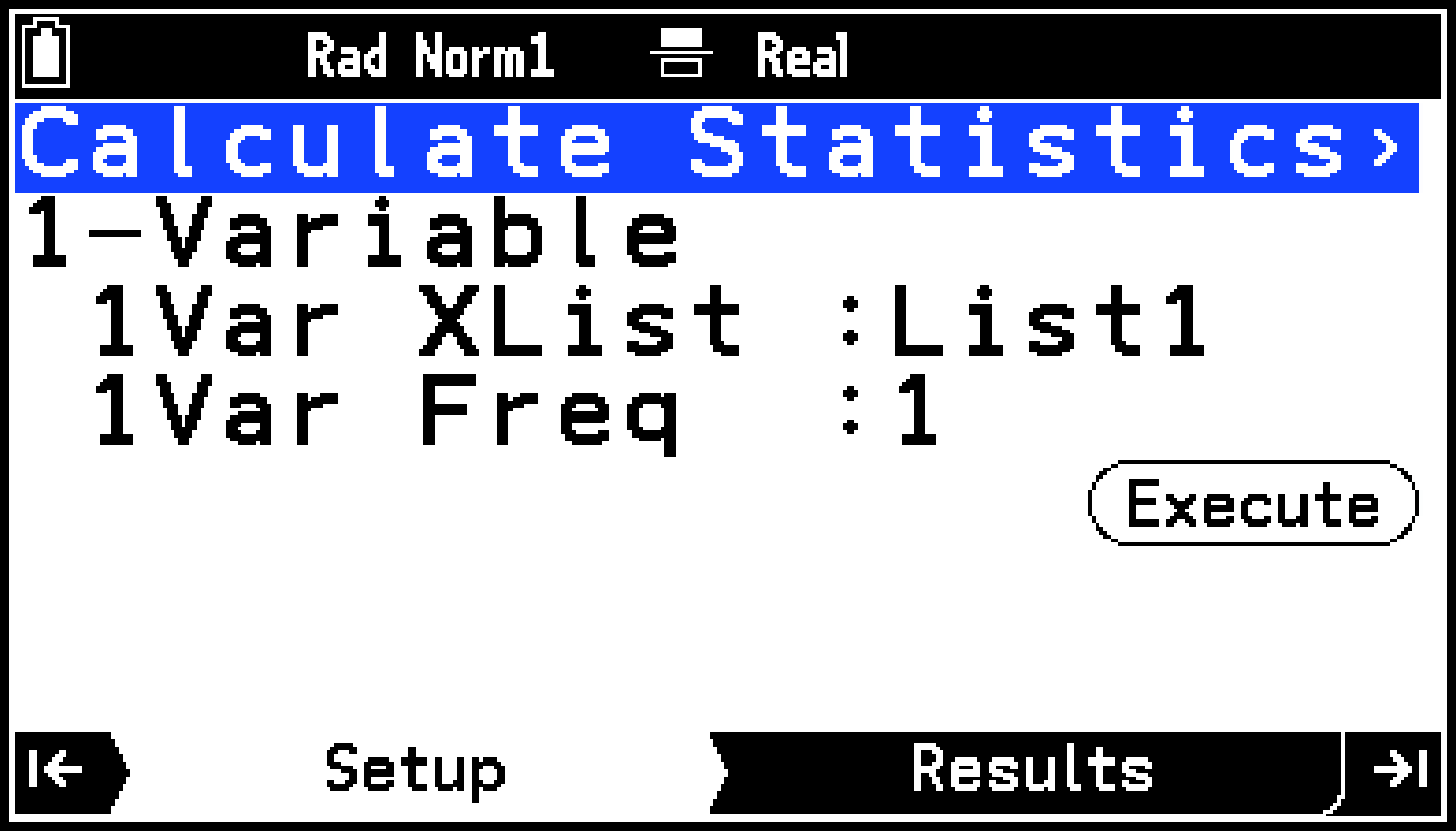
Setupタブの2行目を反転させ、Oを押す。
-
表示されるメニューから、統計計算の種類を選ぶ。
-
必要に応じて、統計データとして使うリストを指定する。
-
[1Var XList]を反転させ、Oを押す。
-
表示されるダイアログに、データとして使うリスト変数の番号を入力し、Oを押す。
-
[1Var Freq]を反転させ、Oを押す。
-
[2Var XList]を反転させ、Oを押す。
-
表示されるダイアログに、XListのデータとして使うリスト変数の番号を入力し、Oを押す。
-
[2Var YList]を反転させ、Oを押す。
-
表示されるダイアログに、YListのデータとして使うリスト変数の番号を入力し、Oを押す。
-
[2Var Freq]を反転させ、Oを押す。
-
>を押す。または、
 を反転させOを押す。
を反転させOを押す。
List Editorにデータを入力し、必要なだけリスト変数を作成します。詳しくはデータを入力するを参照してください。
Calculate Statisticsメニューが、Setupタブに表示されます。
|
これをするには: |
このメニュー項目を選ぶ: |
|---|---|
|
1変数(X)の統計データに基づく要約統計量を一覧表示する |
1-Variable(1変数統計計算) |
|
2変数(X, Y)の統計データに基づく要約統計量を一覧表示する |
2-Variable(2変数統計計算) |
|
2変数(X, Y)の統計データに基づく回帰モデル情報を一覧表示する |
Linear Regression(a+b)(1次回帰(a+b)) |
|
Linear Regression(a+b)(1次回帰(a+b)) |
|
|
Med-Med Regression(Med-Med回帰) |
|
|
Quadratic Regression(2次回帰) |
|
|
Cubic Regression(3次回帰) |
|
|
Quartic Regression(4次回帰) |
|
|
Logarithm Regression(対数回帰) |
|
|
Exp Regression(a・e^b)(指数回帰(a・e^b)) |
|
|
Exp Regression(a・b^)(指数回帰(a・b^)) |
|
|
Power Regression(べき乗回帰) |
|
|
Sinusoidal Regression(sin回帰) |
|
|
Logistic Regression(ロジスティック回帰) |
1変数統計データの場合:
2変数統計データの場合:
手順4で選んだ一覧(要約統計量または回帰モデル情報)が、Resultsタブに表示されます。ウインドウ右端にスクロールバーが表示されているときは、dまたはuを使って表示をスクロールできます。
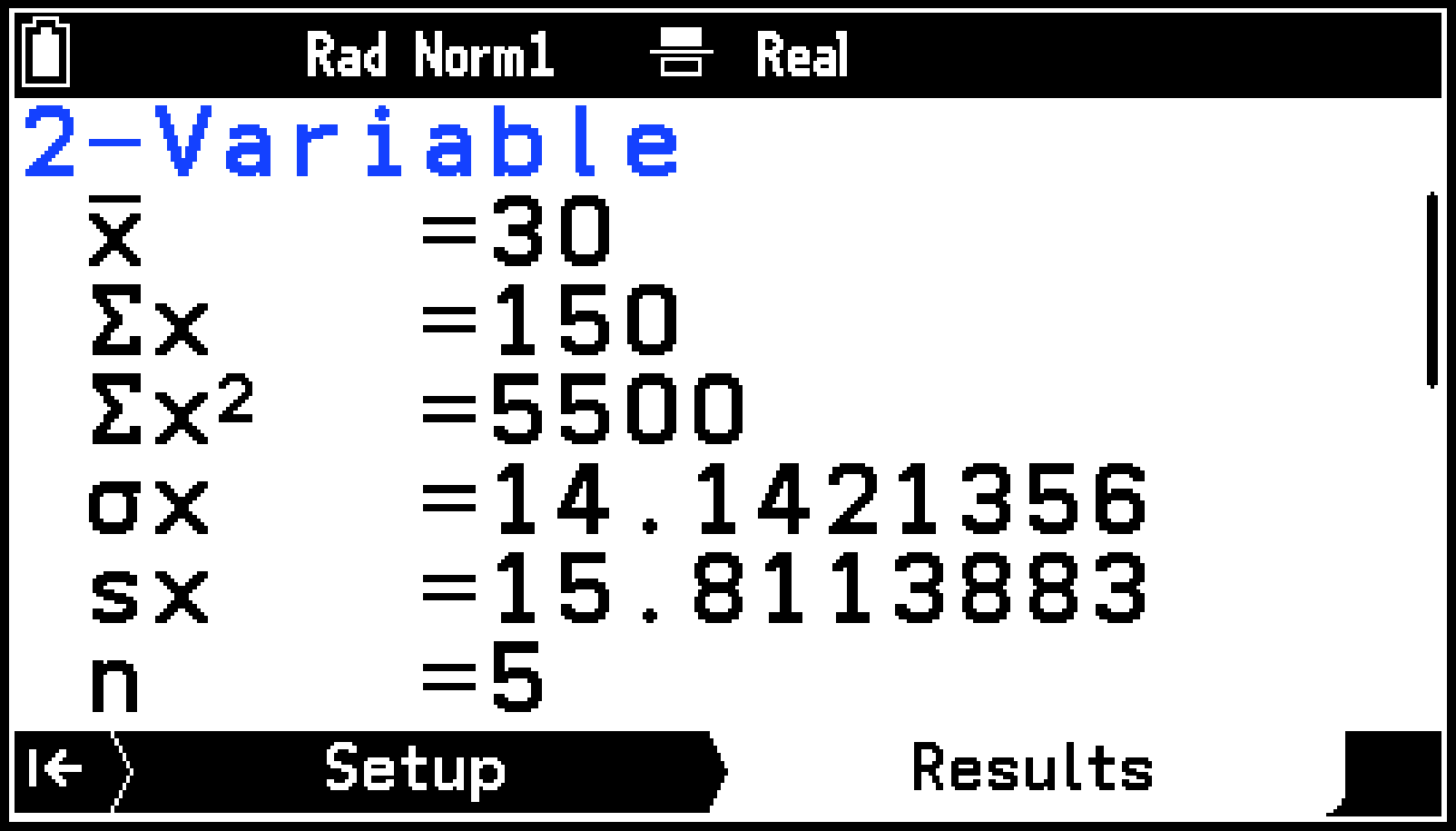
要約統計量
1-Variable
|
平均 |
|
|
総和 |
|
|
二乗和 |
|
|
母標準偏差 |
|
|
標本標準偏差 |
|
|
n |
データ数 |
|
minX |
最小値 |
|
Q1 |
第1四分位点* |
|
Med |
データの中間値 |
|
Q3 |
第3四分位点* |
|
maxX |
最大値 |
|
Mod |
データの最頻値 |
|
Mod:n |
データの最頻値の個数 |
|
Mod:F |
データの最頻値の度数 |
Q1とQ3計算方法は、S> [Q1Q3 Type]の設定に従います。詳しくはQ1Q3 Type(統計)を参照してください。
2-Variable
|
XListデータの平均 |
|
|
XListデータの総和 |
|
|
XListデータの二乗和 |
|
|
XListデータの母標準偏差 |
|
|
XListデータの標本標準偏差 |
|
|
n |
データ数 |
|
YListデータの平均 |
|
|
YListデータの総和 |
|
|
YListデータの二乗和 |
|
|
YListデータの母標準偏差 |
|
|
YListデータの標本標準偏差 |
|
|
XListデータとYListデータの積和 |
|
|
minX |
XListデータの最小値 |
|
maxX |
XListデータの最大値 |
|
minY |
YListデータの最小値 |
|
maxY |
YListデータの最大値 |
参考
上記1-Variableの各要約統計量の値は、C > [Variable Data] > [Statistics] > [X]およびC > [Variable Data] > [Statistics] > [Graph]に含まれる変数に格納されます(Mod:nとMod:Fを除く)。
上記2-Variableの各要約統計量の値は、C > [Variable Data] > [Statistics] > [X]およびC > [Variable Data] > [Statistics] > [Y]に含まれる変数に格納されます。
回帰モデル情報
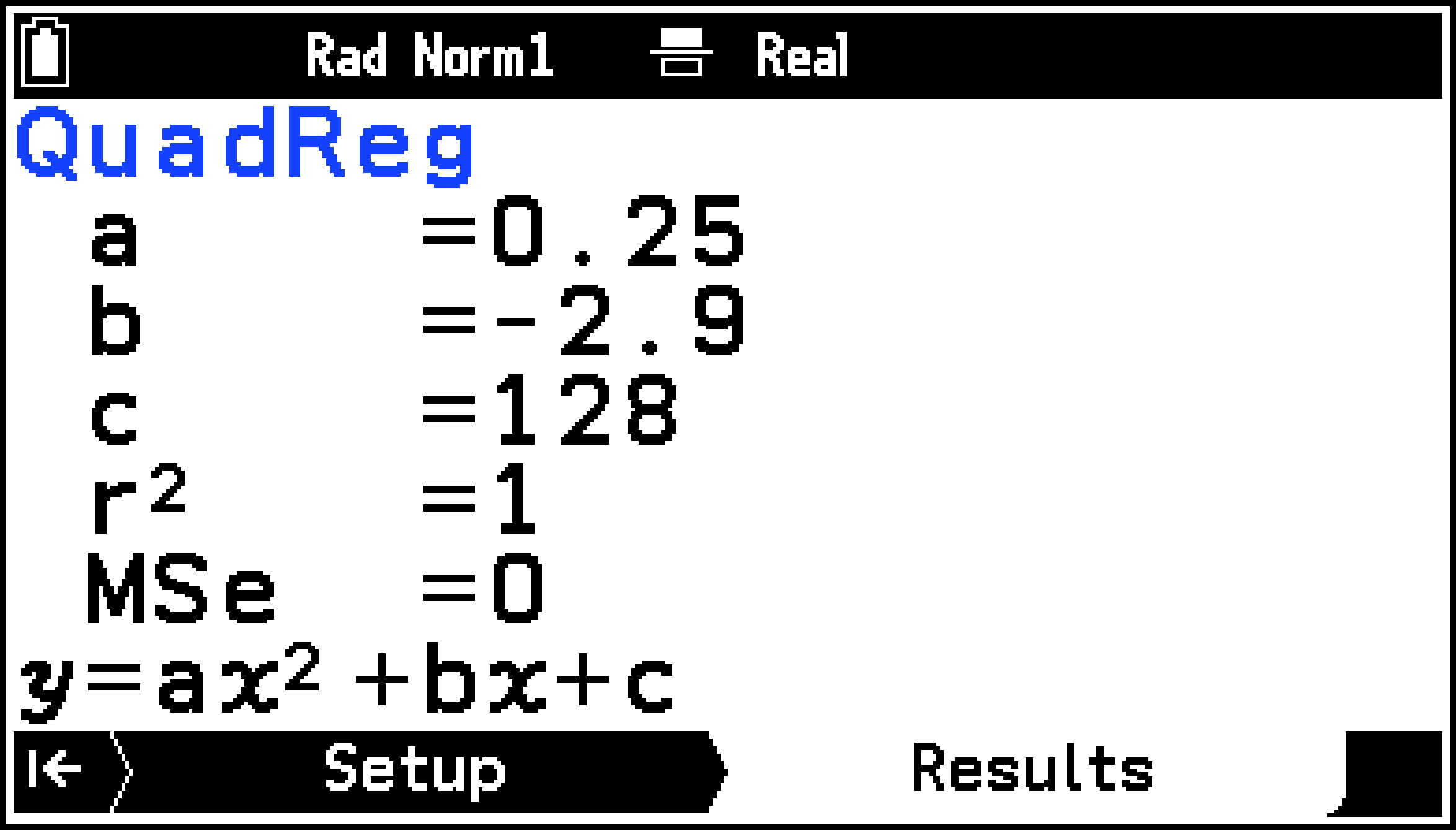
Resultsタブに回帰モデル情報を表示しているときは、1行目に回帰モデル名、最下行に回帰式が表示されます。回帰モデルに応じて表示される情報は、下表のとおりです。
|
回帰モデル |
表示される情報* |
|---|---|
|
Linear Regression(a+b)(1次回帰(ax+b)) |
、、、、MSe |
|
Linear Regression(a+b)(1次回帰(a+bx)) |
、、、、MSe |
|
Med-Med Regression(Med-Med回帰) |
、 |
|
Quadratic Regression(2次回帰) |
、、、、MSe |
|
Cubic Regression(3次回帰) |
、、、、、MSe |
|
Quartic Regression(4次回帰) |
、、、、、、MSe |
|
Logarithm Regression(対数回帰) |
、、、、MSe |
|
Exp Regression(a・e^b)(指数回帰(a・e^bx)) |
、、、、MSe |
|
Exp Regression(a・b^)(指数回帰(a・b^x)) |
、、、、MSe |
|
Power Regression(べき乗回帰) |
、、、、MSe |
|
Sinusoidal Regression(sin回帰) |
、、、、MSe |
|
Logistic Regression(ロジスティック回帰) |
、、、MSe |
、、、、: 回帰係数、: 相関係数、: 決定係数、MSe: 平均平方誤差
参考
上記表中の「表示される情報」列の各値は、C > [Variable Data] > [Statistics] > [Graph]に含まれる変数に格納されます。
Med-Med Regression(Med-Med回帰)の計算を実行すると、3組のサマリーポイント座標(, ; , ; , )の各値が、C > [Variable Data] > [Statistics] > [Point Coordinates]に含まれる変数に格納されます。
回帰モデル情報の表示中にできること
Resultsタブに回帰モデル情報を表示しているときは、下記の操作ができます。
|
これをするには: |
このように操作する: |
|---|---|
|
計算結果の回帰式をファンクション変数に保存する |
|
|
実際のデータ(, )と回帰モデルによる計算値(, )の残差(-)を求め、リスト変数に保存する |
|
何も保存されていない関数式番号を選んでください。上書き保存はできません。
内容が空のリスト番号を入力してください。上書き保存はできません。
統計グラフを描く
2変数の統計データからは、散布図や各種の回帰グラフを描画できます。1変数の統計データからは、ヒストグラムや箱ひげ図をはじめとする7種類のグラフを描画できます。グラフを描いた後で、要約統計量や回帰モデル情報を表示することも可能です。
初期設定を使って散布図と回帰グラフを描く
ここでは2変数の統計データから散布図を描き、その散布図に重ねて回帰グラフを描きます。
-
List Editorを使って、下記のデータを入力する。
-
Statisticsアプリで実行したいことを選ぶに従って操作し、[Draw Statistics Graph](統計グラフの描画)を選ぶ。
-
[Graph1]を反転させ、Oを押す。
-
>を押す。
-
>を押す。表示されるメニューから、[Quadratic Regression](2次回帰)を選ぶ。
-
>を押す。
|
List 1 |
List 2 |
|
11 |
1.5 |
|
21 |
2.2 |
|
32 |
3.4 |
|
43 |
5.1 |
|
59 |
8.7 |
詳しくはデータを入力するを参照してください。
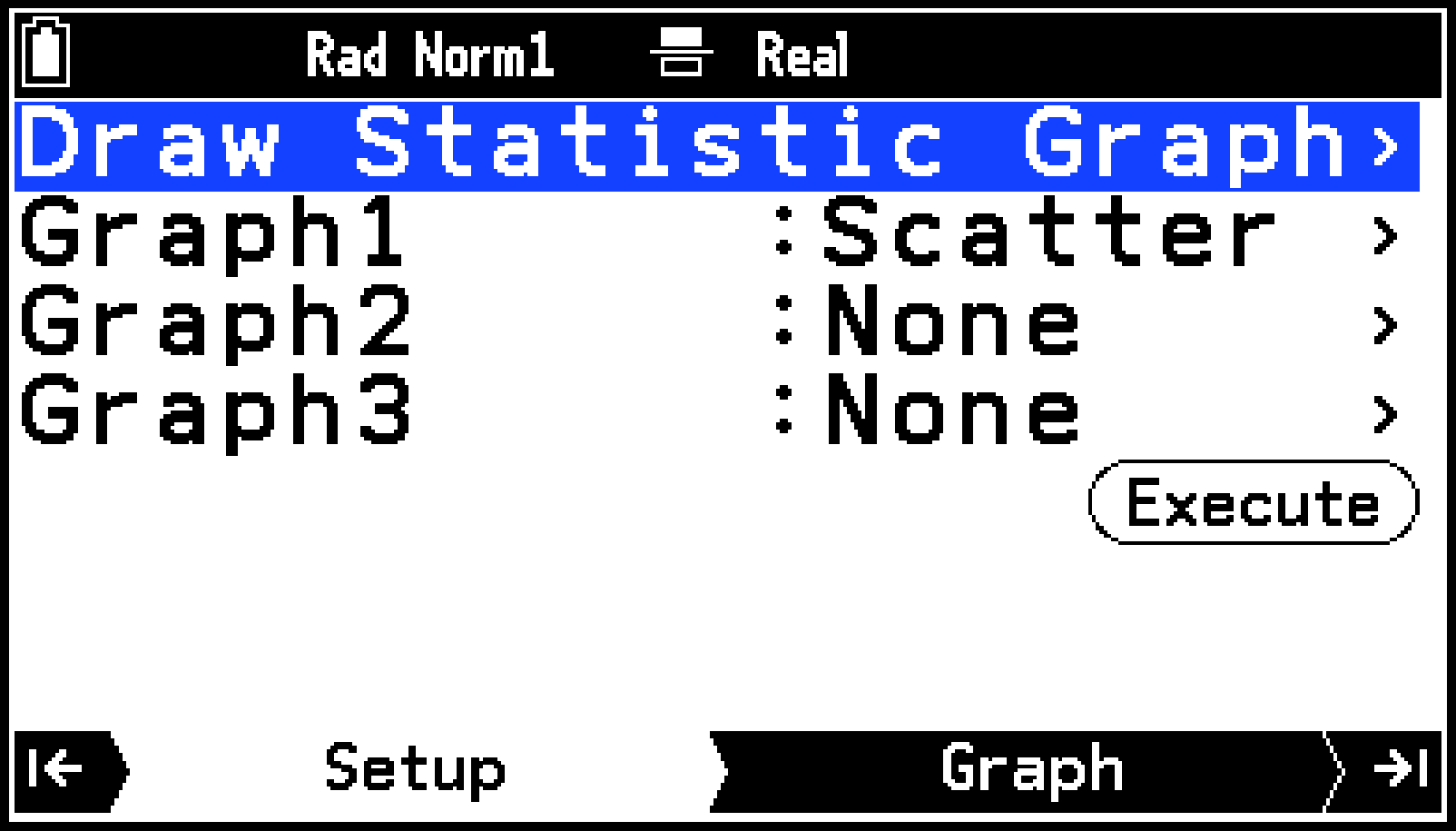
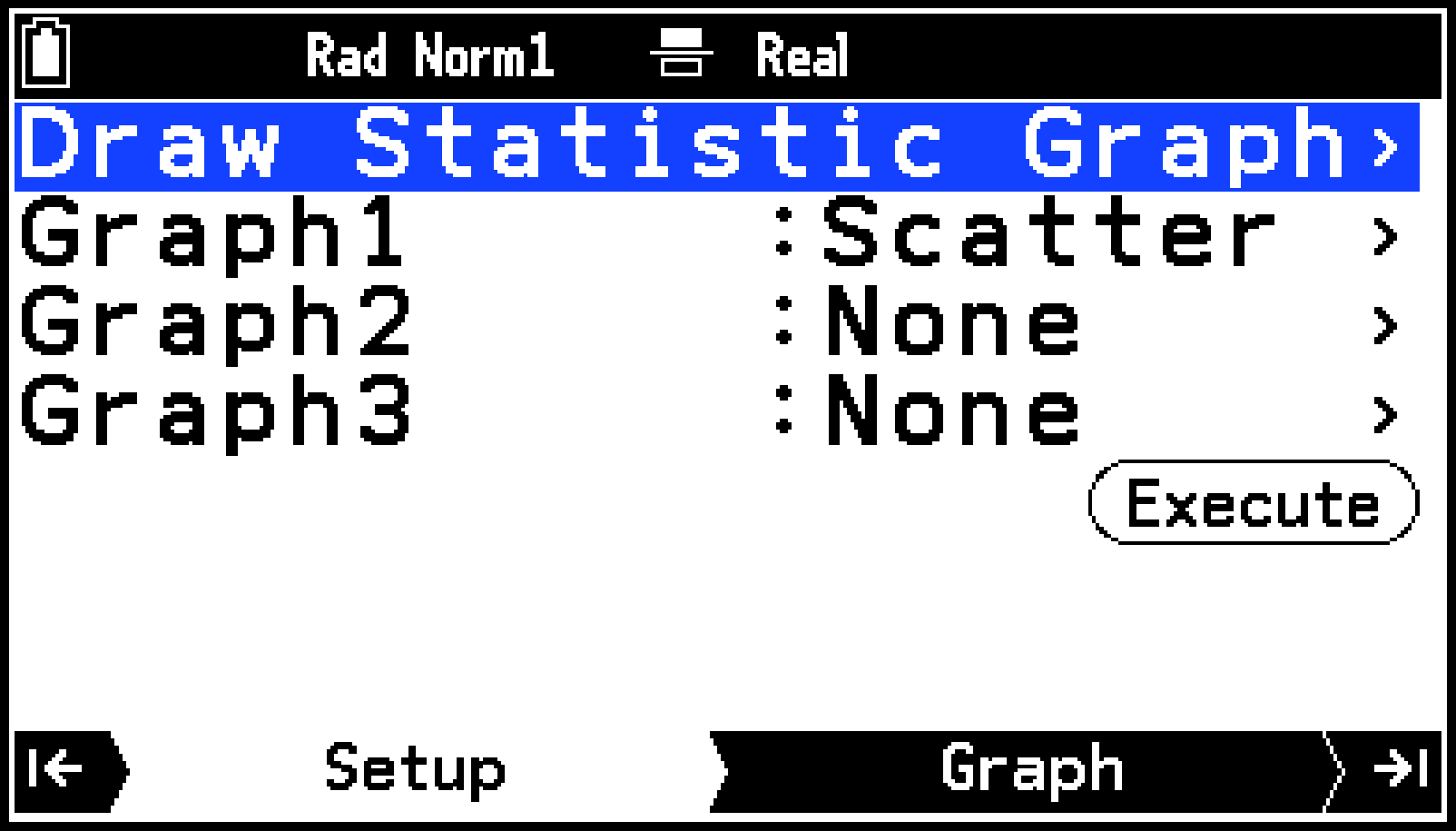
Draw Statistics Graphメニューが、Setupタブに表示されます。初期設定では、Graph1はScatter(散布図)、Graph2とGraph3は None(グラフを描かない)に設定されています。
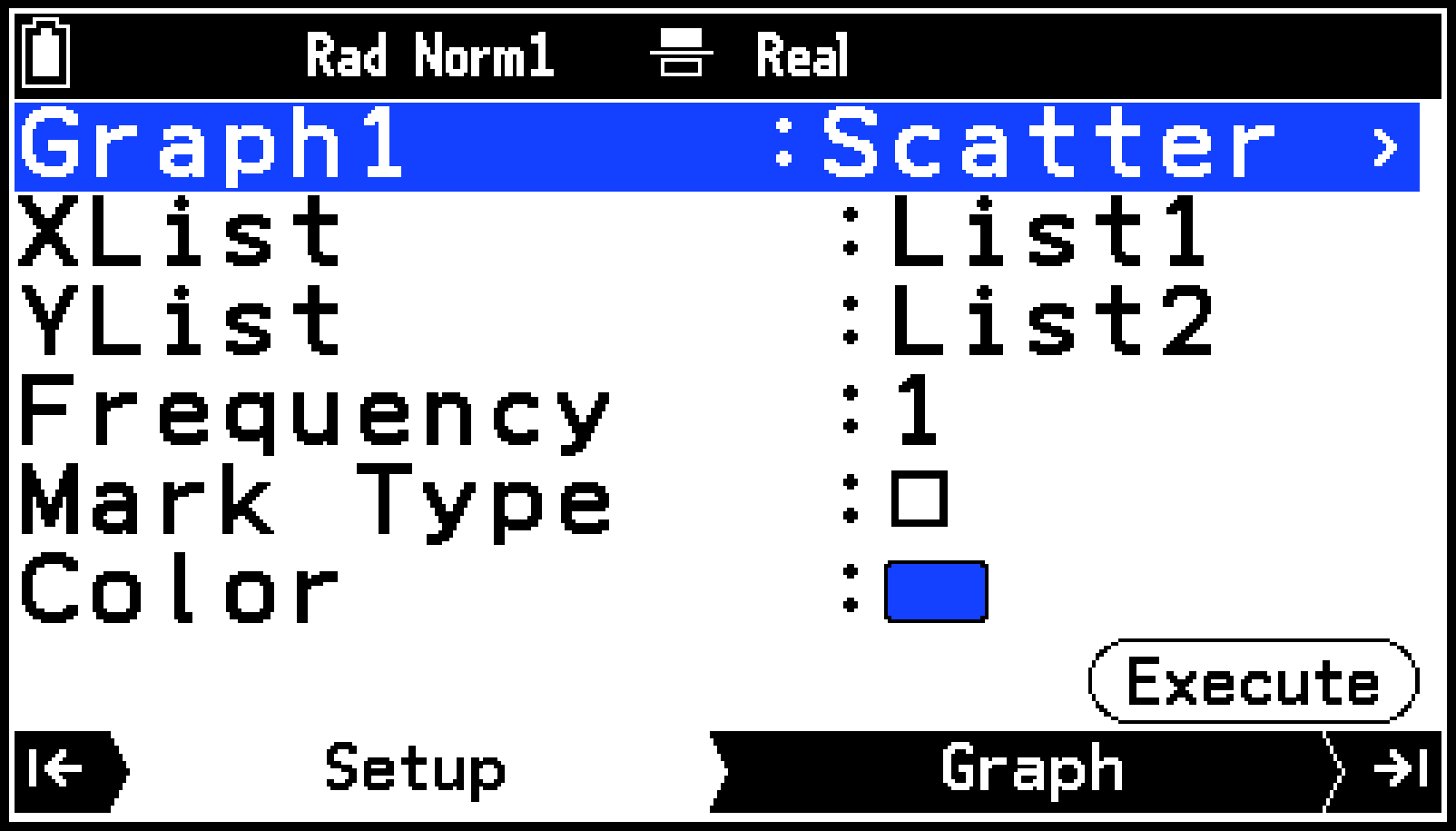
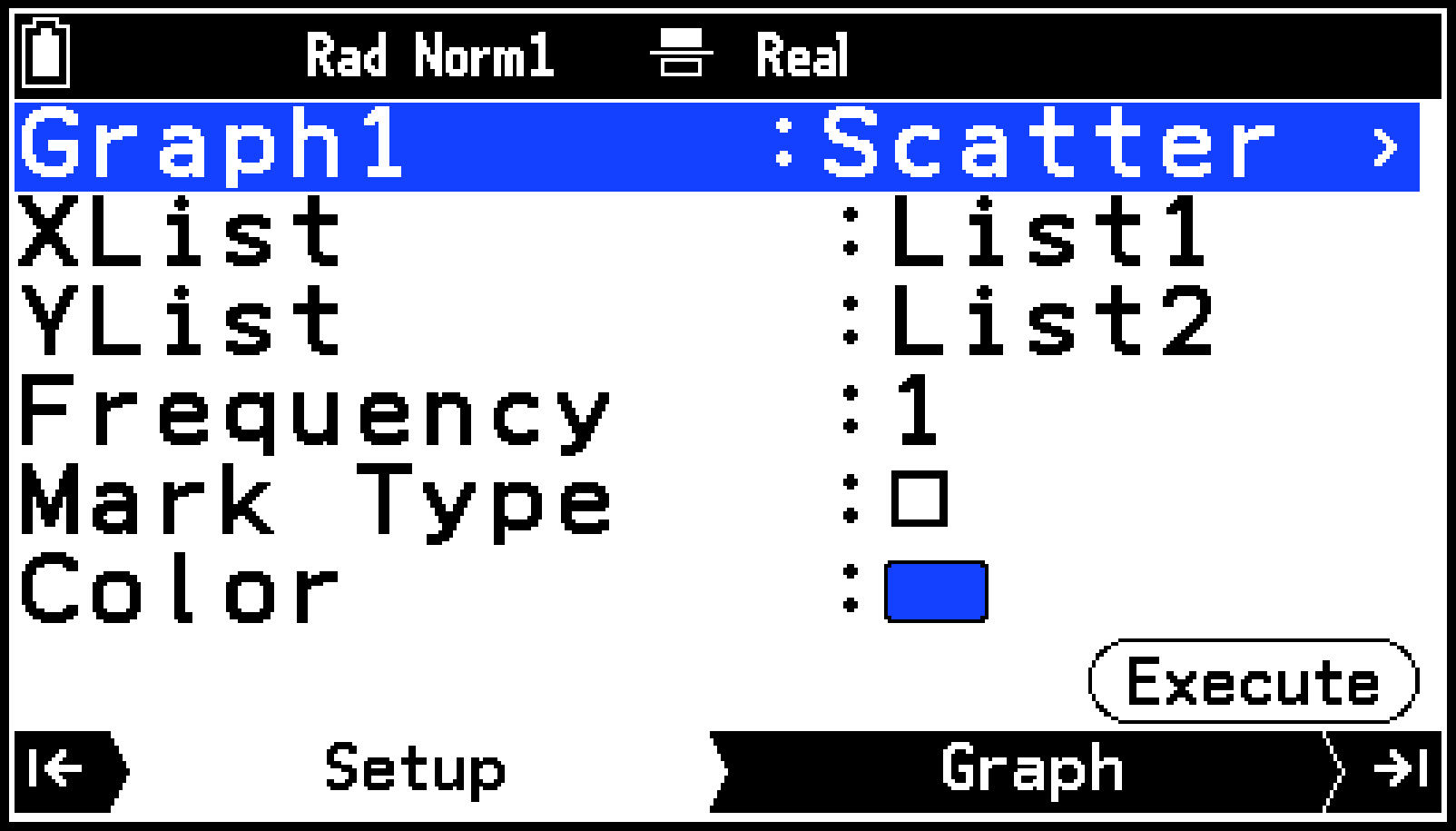
Setupタブの表示が、Graph1の設定メニューに切り替わります。
初期設定では、XListにList1、YListにList2が割り当てられています。また、Frequencyは1です。
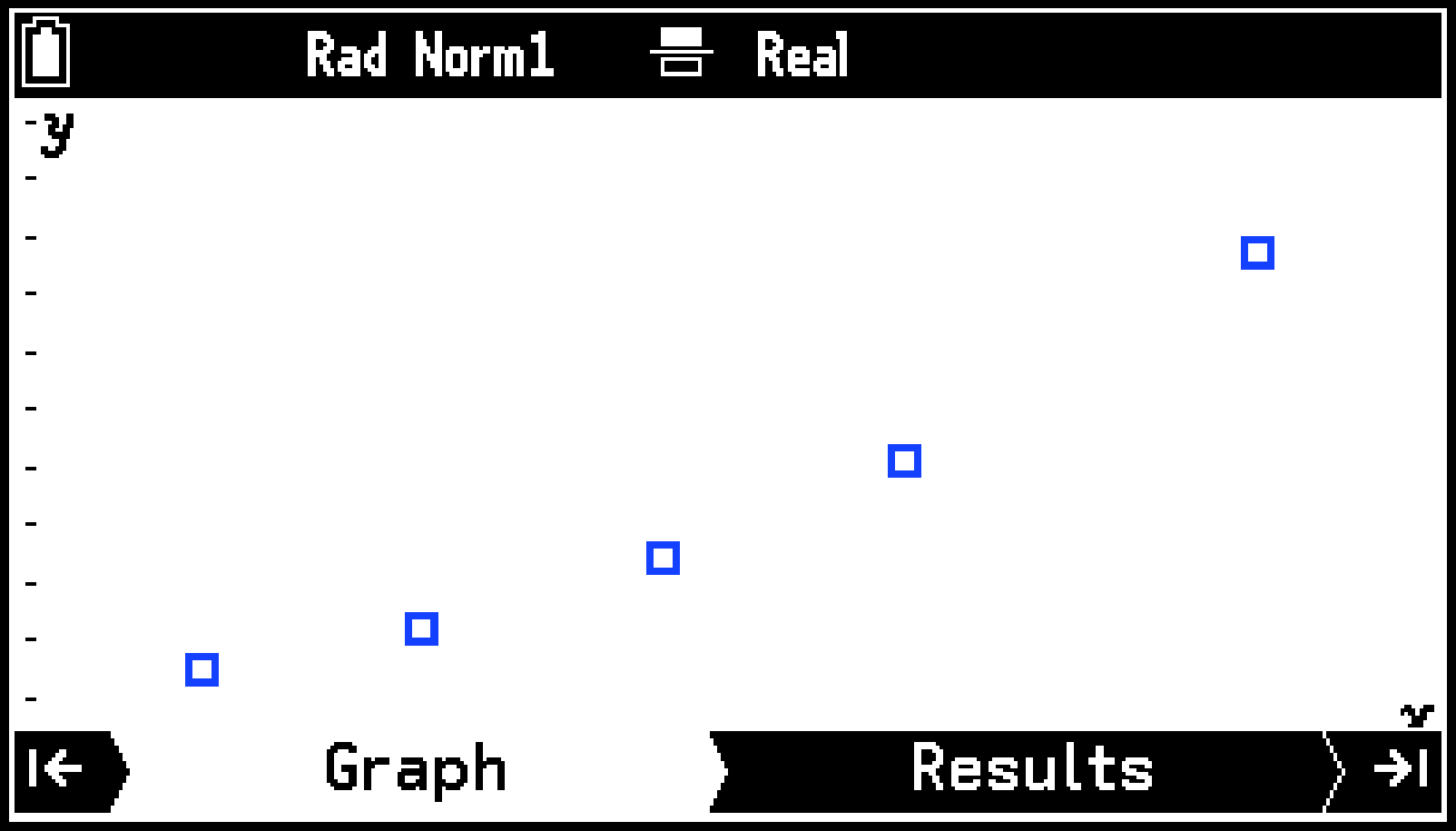
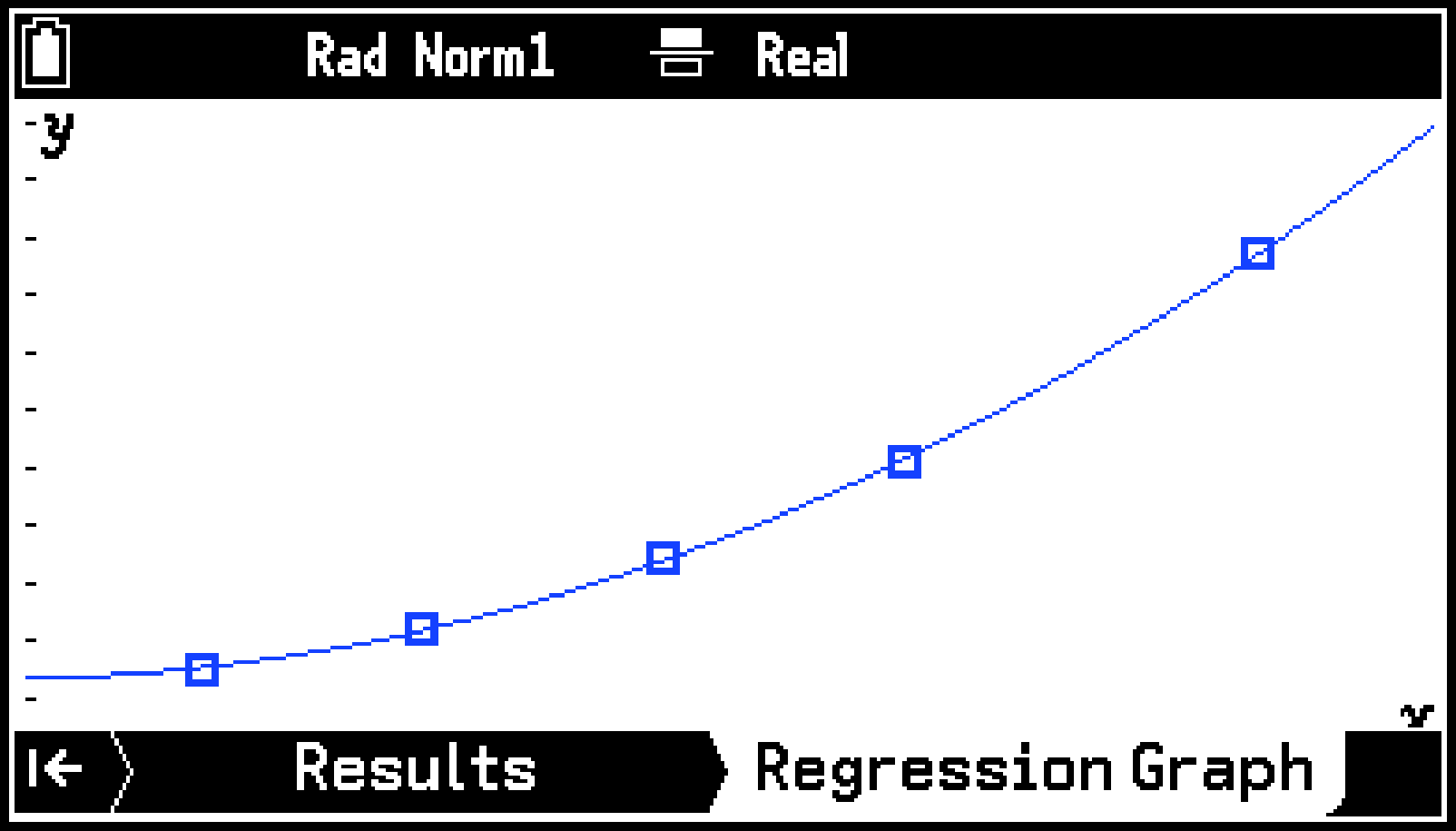
List1のデータを軸、List2のデータを軸として、散布図が描かれます。
データに2次回帰モデルが適用され、計算結果が一覧表示されます。
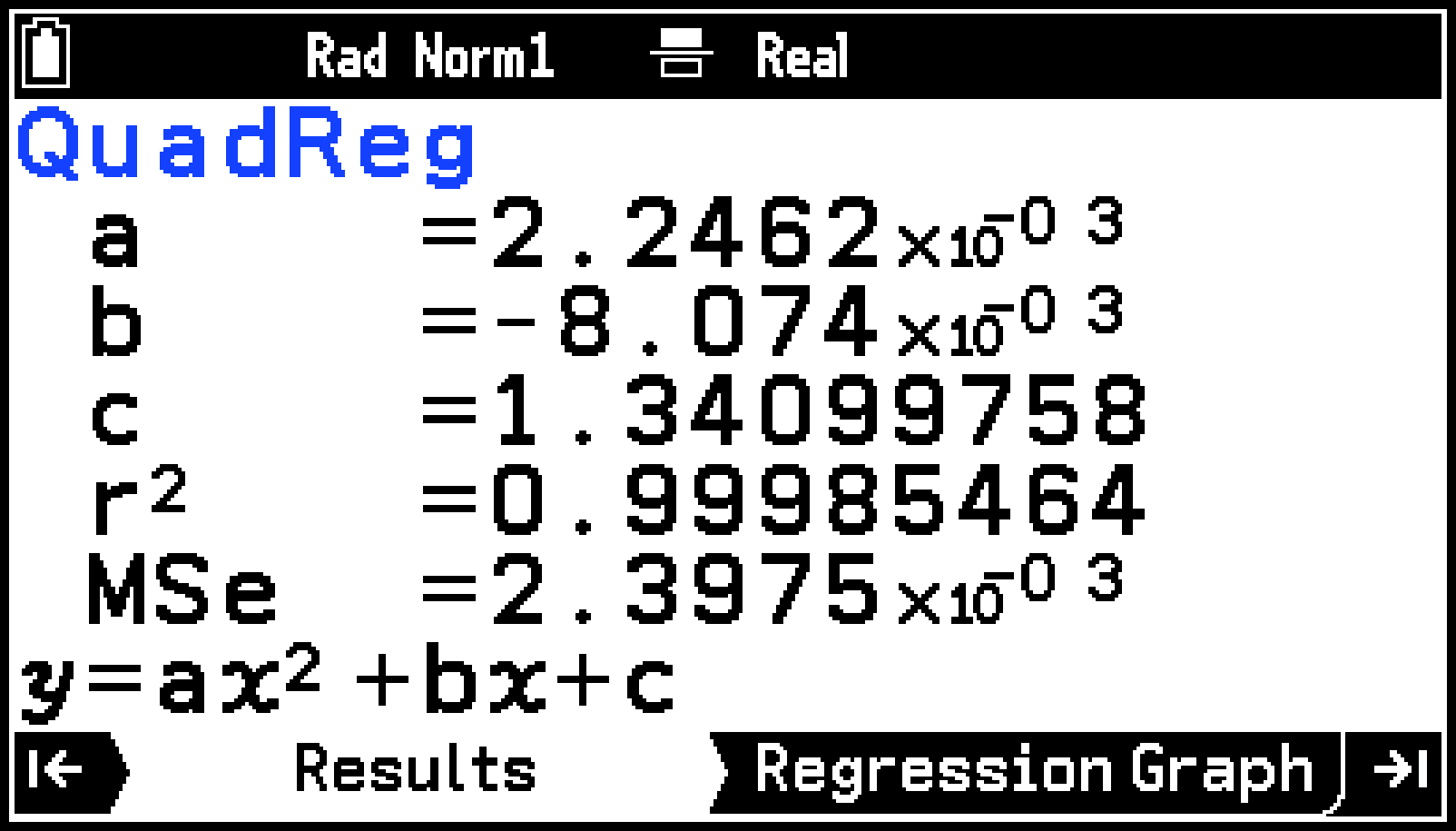
2次回帰グラフが、散布図に重ねて描かれます。
参考
上記手順2のSetupタブのGraph1~Graph3については、複数のグラフ設定を使ってグラフを描くを参照してください。
上記手順4のGraphタブと上記手順6のRegression Graphタブでできる操作について詳しくは、グラフウインドウでの各種操作を参照してください。
上記手順5のResultsタブに表示される値の意味は、回帰モデル情報を参照してください。
1変数の統計グラフを描く(ヒストグラムや箱ひげ図など)
List Editorに入力した1変数の統計データに基づいて、下記のことができます。
-
Box Plot(箱ひげ図)・Histogram(ヒストグラム)・Broken Line Graph(折れ線グラフ)・Pie Chart(円グラフ)・Bar Graph(棒グラフ)・Normal Probability Plot(正規確率プロット)・Normal Density Curve(正規分布曲線)を描く
-
グラフを描いた後で、要約統計量を一覧表示する(Pie Chartを除く)
操作の流れ
-
List Editorにデータを入力する。
-
Statisticsアプリで実行したいことを選ぶに従って操作し、[Draw Statistics Graph](統計グラフの描画)を選ぶ。
-
描くグラフの種類を選ぶ。
-
[Graph1]を反転させ、Oを押す。
-
もう一度Oを押す。
-
メニューから描くグラフの種類を選び、Oを押す。
-
統計データとして使うリストを指定する。
-
[XList]を反転させ、Oを押す。
-
表示されるダイアログに、データとして使うリスト変数の番号を入力し、Oを押す。
-
[Frequency]を反転させ、Oを押す。(Normal Probability Plotを除く)
-
[Data]を反転させ、Oを押す。
-
表示されるダイアログに、データのカテゴリー名として使うリスト変数の番号を入力し、Oを押す。
-
[Data1]を反転させ、Oを押す。
-
表示されるダイアログに、データとして使うリスト変数の番号を入力し、Oを押す。
-
[Data2]、[Data3]についても、上記手順(1)、(2)の操作を繰り返す。
-
必要に応じて、グラフの色などを指定する。
-
グラフを描くには、>を押す。または、
を反転させOを押す。 -
要約統計量の一覧を表示するには、>を押す。(Pie Chartを除く)
詳しくはデータを入力するを参照してください。
Draw Statistics Graphメニューが、Setupタブに表示されます。
Setupタブの表示が、Graph1の設定メニューに切り替わります。
グラフの種類を選ぶメニューが表示されます。
Box Plot(箱ひげ図)・Histogram(ヒストグラム)・Broken Line Graph(折れ線グラフ)・Normal Probability Plot(正規確率プロット)・Normal Density Curve(正規分布曲線)の場合:
Pie Chart(円グラフ)の場合:
円グラフの描画に使うことができるリスト変数のデータ数(リストの行数)は、最大20です。
Bar Graph(棒グラフ)の場合:
棒グラフを描くためのデータとして、最大3つのリスト変数を指定できます。
2つまたは3つのリスト変数を使う場合は、必ずすべてのリスト変数の要素数を同じにしてください。同じでない場合はエラー(Dimension ERROR)となります。
2つのリスト変数を使う場合は、[Data1]と[Data2]に割り当ててください。[Data1]と[Data3]にリスト変数を割り当て、[Data2]をNoneに設定すると、エラー(Condition ERROR)となります。
詳しくは1変数統計グラフの種類に応じた指定項目を参照してください。
グラフがGraphタブに表示されます。
手順3-(2)で選んだグラフがHistogramまたはBroken Line Graphの場合、ここでStart(グラフを描き始める座標)とWidth(グラフの描画幅)を指定するダイアログが表示されます。それぞれの数値を入力し、![]() を反転させ、Oを押します。
を反転させ、Oを押します。
Graphタブでできる操作については、グラフウインドウでの各種操作を参照してください。
一覧がResultsタブに表示されます。dまたはuを使って表示をスクロールできます。
一覧に表示される値の意味は、要約統計量を参照してください。
1変数統計グラフの種類に応じた指定項目
Box Plot(箱ひげ図)
Outliers:
箱ひげ図に外れ値のドットを表示するか、しないか指定します。
[On]: 表示する
[Off]: 表示しない
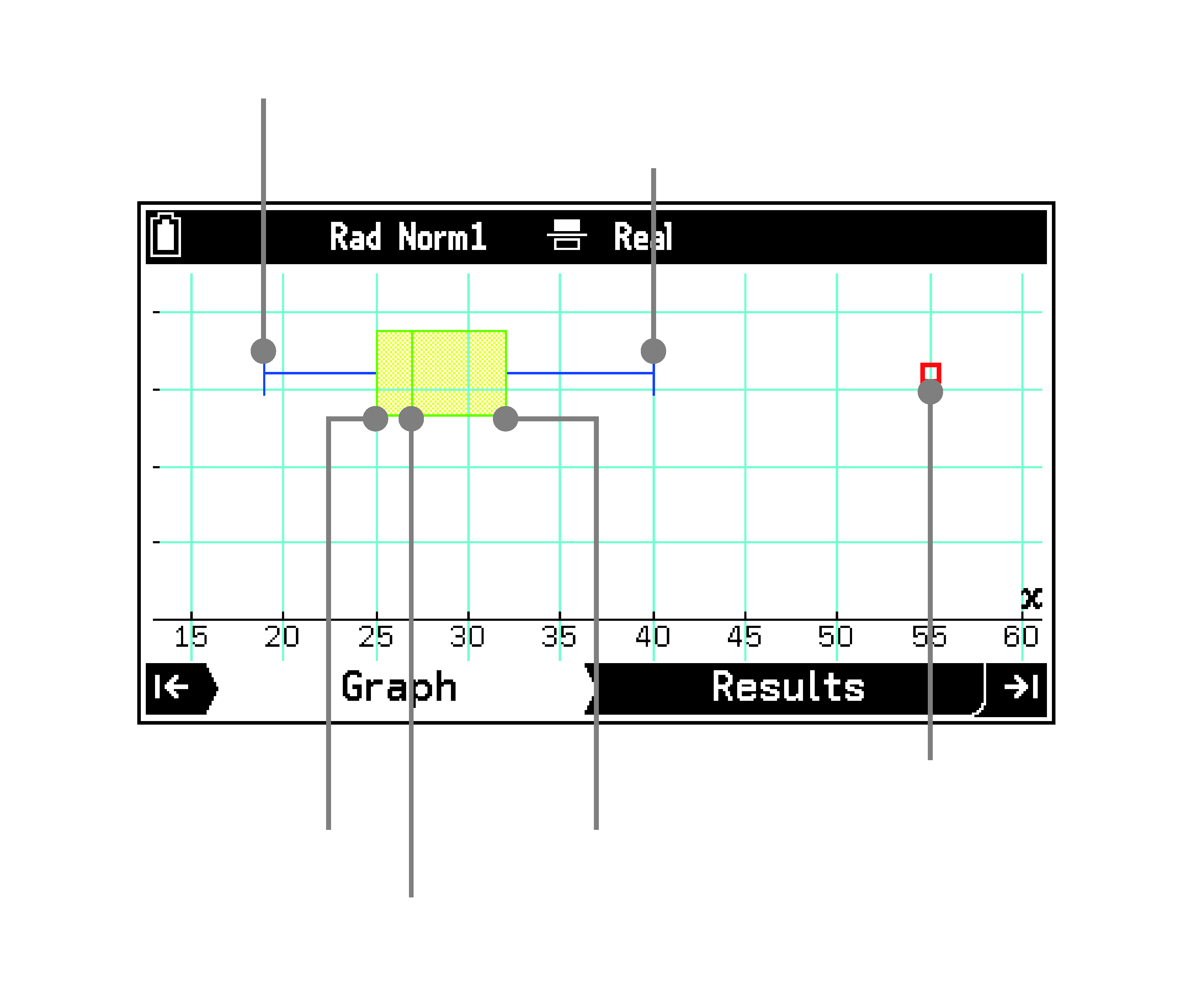
minX(最小値)
Q1(第1四分位点)
Med(中間値)
Q3(第3四分位点)
maxX(最大値)
外れ値のドット
Box:
Q1からQ3を囲む箱部分の縁線、およびMedの線の色を指定します。
Whisker:
箱の両端からminX、maxXに伸びる線の色を指定します。
OutlierColor:
外れ値のドットの色を指定します。
Box Inside:
Q1からQ3を囲む箱部分の内部の色を指定します。
- Area Color:
塗りの色を指定します。
[Auto]を選ぶと、Q1からMedまでの箱の内側を青、MedからQ3までの箱の内側を黄色で塗り分けます。
- Paint Style:
塗りの濃さを指定します。
[Normal]: 標準の濃さで塗る
[Lighter]: 淡い色で塗る
参考
S > [Q1Q3 Type]の設定を変更すると、同じデータに基づいて箱ひげ図を描画しても、Q1、Q3の位置が変わることがあります。
Histogram(ヒストグラム)
Area:
ヒストグラムの内部の色を指定します。
- Area Color:
塗りの色を指定します。
[Auto]を選ぶと、各データを青・赤・緑・マゼンタ・シアン・黄色の順で繰り返し、自動的に塗り分けます。
- Paint Style:
Box Plot(箱ひげ図)と同様です。
Border:
ヒストグラムの縁線の色を指定します。[Clear]を選ぶと、縁線が描かれません。
Broken Line Graph(折れ線グラフ)
Color:
グラフの描画色を指定します。
Pie Chart(円グラフ)
Display:
データの表示形式を指定します。
[%]: パーセンテージで表示する
[Data]: 数値で表示する
Pie Area:
円グラフの内部の色を指定します。
- Area Color:
Histogram(ヒストグラム)と同様です。
- Paint Style:
Box Plot(箱ひげ図)と同様です。
Pie Border:
円グラフの縁線の色を指定します。[Clear]を選ぶと、縁線が描かれません。
Bar Graph(棒グラフ)
Stick Style:
棒の向きを指定します。
[Length]:縦向き
[Horizontal]:横向き
D1 Area、D2 Area、D3 Area:
Data1、Data2、Data3の各棒グラフの内部の色を指定します。
- Area Color:
Histogram(ヒストグラム)と同様です。
- Paint Style:
Box Plot(箱ひげ図)と同様です。
D1 Border、D2 Border、D3 Border:
Data1、Data2、Data3の各棒グラフの縁線の色を指定します。[Clear]を選ぶと、縁線が描かれません。
Normal Probability Plot(正規確率プロット)
Mark Type:
プロットに使うマークを指定します。
Color:
グラフの描画色を指定します。
Normal Density Curve(正規分布曲線)
Color:
グラフの描画色を指定します。
2変数の統計グラフを描く(散布図や回帰グラフ)
List Editorに入力した2変数の統計データに基づいて、下記のことができます。
-
Scatter Plot(散布図)・xy Line Graph(線図)・Regression Graph(回帰グラフ)を描く
-
グラフを描いた後で、要約統計量または回帰モデル情報を一覧表示する
-
回帰グラフを(1)のグラフに重ねて描く*
(1)で散布図を描き、それに重ねて回帰グラフを描くのが一般的です。線図や回帰グラフに重ねて回帰グラフを描くことも可能です。
操作の流れ
-
List Editorにデータを入力する。
-
Statisticsアプリで実行したいことを選ぶに従って操作し、[Draw Statistics Graph](統計グラフの描画)を選ぶ。
-
描くグラフの種類を選ぶ。
-
[Graph1]を反転させ、Oを押す。
-
もう一度Oを押す。
-
メニューから描くグラフの種類を選び、Oを押す。
-
統計データとして使うリストを指定する。
-
[XList]を反転させ、Oを押す。
-
表示されるダイアログに、XListのデータとして使うリスト変数の番号を入力し、Oを押す。
-
[YList]を反転させ、Oを押す。
-
表示されるダイアログに、YListのデータとして使うリスト変数の番号を入力し、Oを押す。
-
[Frequency]を反転させ、Oを押す。(Sinusoidal Regression Graph、Logistic Regression Graphを除く)
-
必要に応じて、グラフの色などを指定する。
-
グラフを描くには、>を押す。または、
を反転させOを押す。 -
要約統計量または回帰モデル情報の一覧を表示する。
-
>を押す。
-
下表のとおりに操作する。
-
Oを押す。
-
回帰グラフを描くためのRegression Graphタブに移動するには、>を押す。
-
必要に応じて、回帰グラフを追加する。
-
T > [Draw Regression Graph]を選ぶ。
-
表示されるメニューから希望する回帰モデルを選び、Oを押す。
詳しくはデータを入力するを参照してください。
Draw Statistics Graphメニューが、Setupタブに表示されます。
Setupタブの表示が、Graph1の設定メニューに切り替わります。
グラフの種類を選ぶメニューが表示されます。
メニューには、1変数と2変数の両方のグラフが表示されます。[Scatter Plot](散布図)、[xy Line Graph](線図)、または[** Regression Graph](各種の回帰グラフ、「**」の部分は回帰の種類)の中からいずれか1つを選んでください。
Mark Type: グラフの種類としてScatter Plot(散布図)またはxy Line Graph(線図)を選択した場合、プロットに使うマークを指定します。
Color: グラフの描画色を指定します。
グラフがGraphタブに表示されます。
Graphタブでできる操作については、グラフウインドウでの各種操作を参照してください。
|
これを一覧表示するには: |
このメニュー項目を選ぶ: |
|---|---|
|
要約統計量 |
2-Variable(2変数統計計算) |
|
回帰モデル情報 |
Linear Regression(a+b)(1次回帰(a+b)) |
|
Linear Regression(a+b)(1次回帰(a+b)) |
|
|
Med-Med Regression(Med-Med回帰) |
|
|
Quadratic Regression(2次回帰) |
|
|
Cubic Regression(3次回帰) |
|
|
Quartic Regression(4次回帰) |
|
|
Logarithm Regression(対数回帰) |
|
|
Exp Regression(a・e^b)(指数回帰(a・e^b)) |
|
|
Exp Regression(a・b^)(指数回帰(a・b^)) |
|
|
Power Regression(べき乗回帰) |
|
|
Sinusoidal Regression(sin回帰) |
|
|
Logistic Regression(ロジスティック回帰) |
手順(2)で選んだ一覧が、Resultsタブに表示されます。
手順7で回帰モデルの1つを選んだ場合は、そのモデルによる回帰グラフが、手順6で描いたグラフに重ねて描かれます。
手順7で2-Variableを選んだ場合は、手順6で描いたグラフだけがそのまま表示されます。
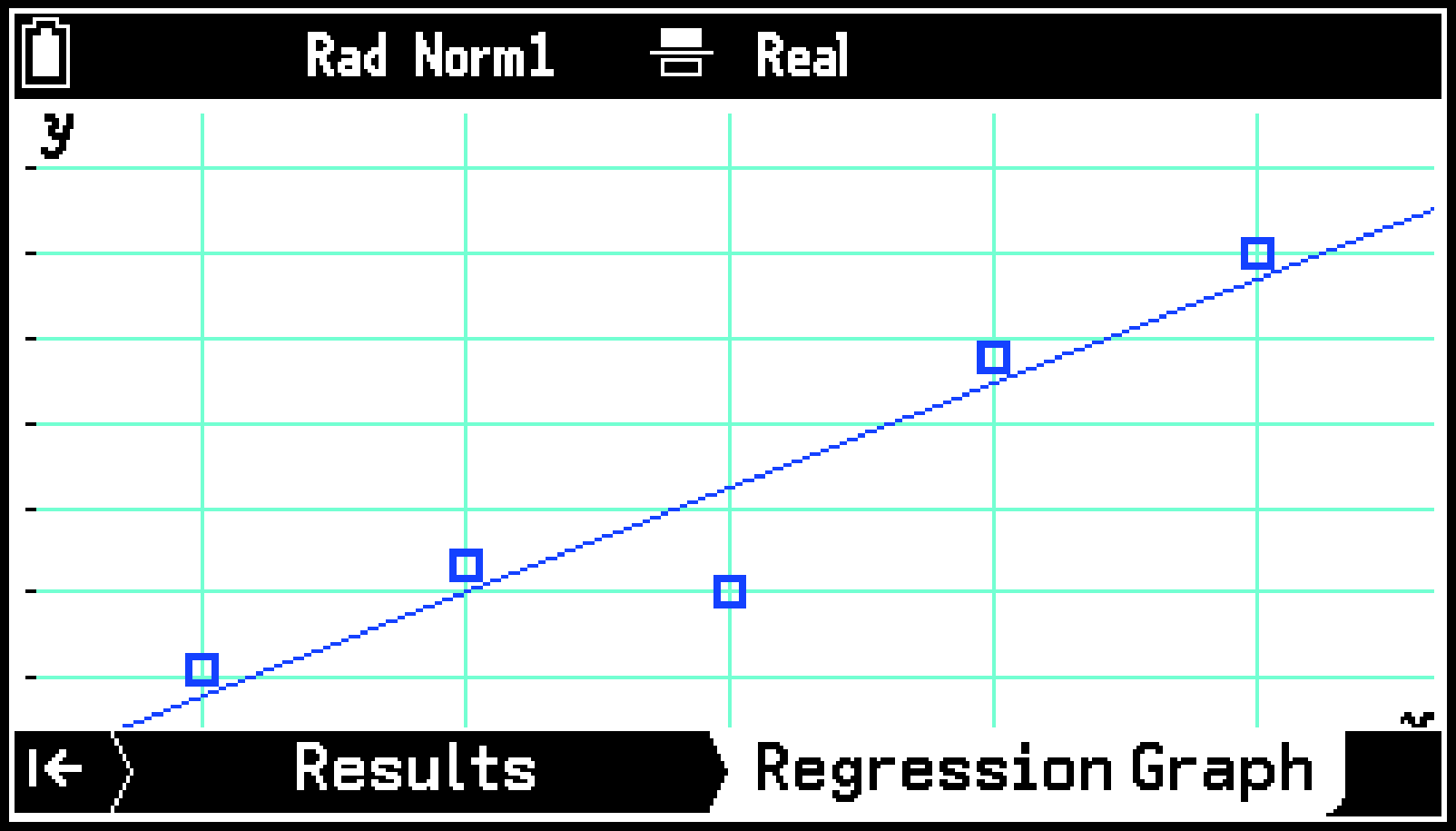
Regression Graphタブでは、複数の回帰グラフを追加できます。下記のとおり操作します。
選んだ回帰モデルのグラフが追加されます。
(1)、(2)の操作を繰り返すことで、さらに回帰グラフを追加できます。
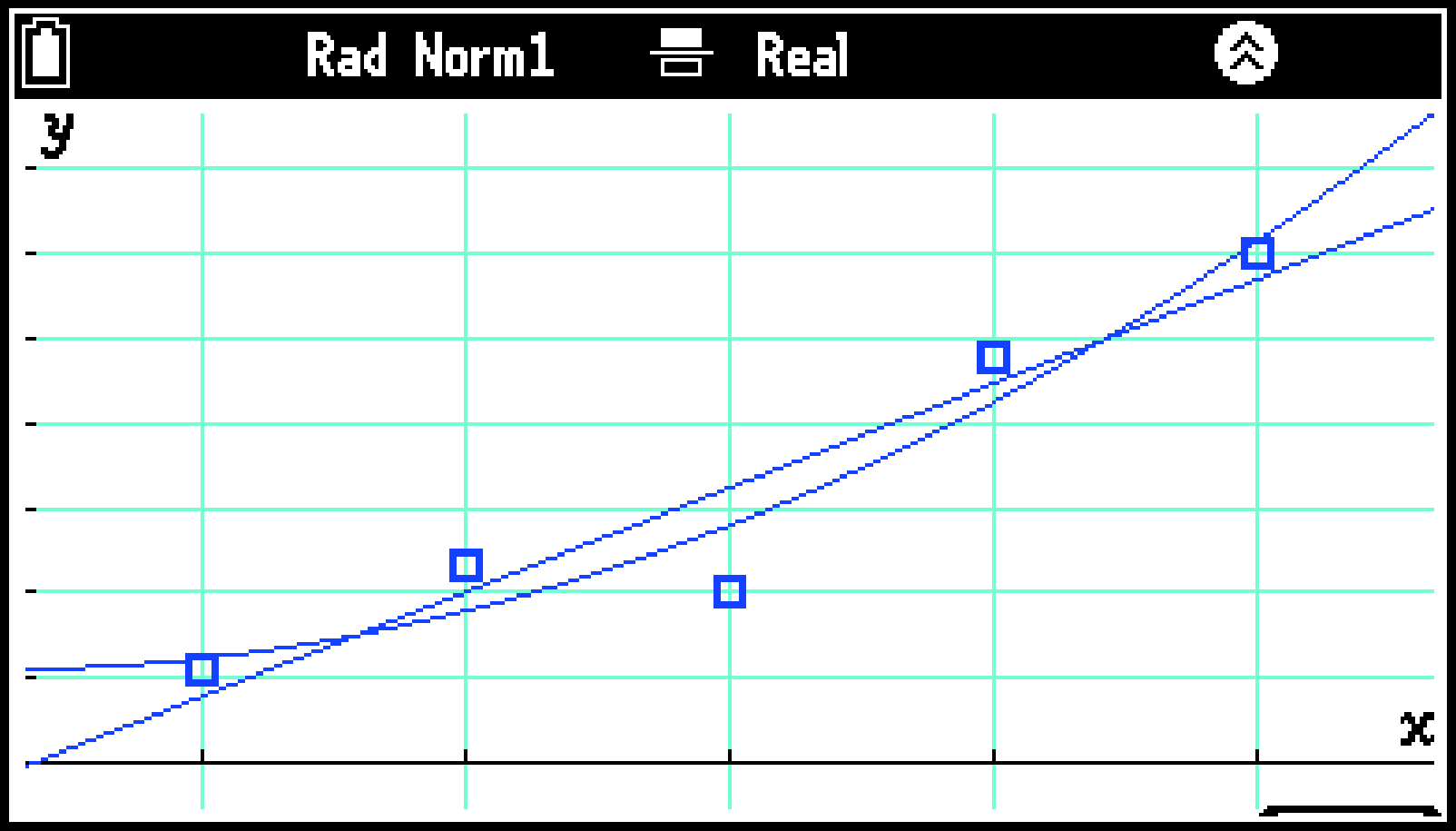
Regression Graphタブでできる操作については、グラフウインドウでの各種操作を参照してください。
グラフウインドウでの各種操作
Statisticsアプリのグラフウインドウ(GraphタブまたはRegression Graphタブ)では、下記の操作が可能です。
円グラフに特有の操作
円グラフの表示中は、下記の操作ができます。
|
これをするには: |
このように操作する: |
|---|---|
|
表示する数値をデータ値とパーセンテージの間で切り替える |
T > [%/Data]を選ぶ。 |
|
表示中の円グラフのパーセンテージ値をリスト変数に保存する |
|
タブを隠すには、表示するには
タブを隠す、表示するを参照してください。
グラフウインドウを上下左右に動かすには
カーソルキーを押します。
グラフウインドウの表示内容を拡大縮小するには
拡大するには+を、縮小するには-を押します。
トレース機能を使うには(Trace)
トレース機能は、グラフ上に十字ポインター(![]() )を表示し、座標値を読み取るための機能です。トレース機能を有効にするには、 T > [Trace]を選びます。トレース機能が有効のときにできる操作は、下表のとおりです。
)を表示し、座標値を読み取るための機能です。トレース機能を有効にするには、 T > [Trace]を選びます。トレース機能が有効のときにできる操作は、下表のとおりです。
|
これをするには: |
このように操作する: |
|---|---|
|
グラフに沿ってポインターを移動する |
lまたはrを押す。 |
|
複数のグラフがあるとき、グラフ間でポインターを移動する |
dまたはuを押す。 |
|
トレース機能を解除する |
bを押す。 |
ズーム機能を使うには(Zoom)
T > [Zoom]に含まれるメニュー項目を使って、グラフウインドウの表示範囲を切り替えることができます。詳しくはグラフウインドウのズーム設定を変更する(Zoom)を参照してください。なおStatisticsアプリのズーム機能に、[Zoom Auto]はありません。
グラフウインドウの表示範囲を指定するには(View Window)
統計グラフの表示範囲設定について(View Window)を参照してください。
スケッチ機能を使うには(Sketch)
グラフの描画域内に、点や線、文字を書き込むことができます。詳しくはスケッチ機能を使うには(Sketch)を参照してください。Statisticsアプリで利用できるメニュー項目は、下記のとおりです。
[Clear Screen]、[Plot]、[Line]、[Circle]、[Vertical Line]、[Horizontal Line]、[Pen]、[Text]
Graph&Tableアプリで入力した関数式のグラフを描くには(Draw Function)
2変数のグラフを表示しているときは、下記操作で関数式のグラフを重ねて描くことができます。
-
T > [Draw Function]を選ぶ。
-
表示されるメニューで描きたい関数式を反転させ、Oを押す。
回帰グラフ上の値に対する値を求めるには(Graph Solve)
回帰グラフを表示しているときは、下記操作で回帰グラフ上の値に対する値を求めることができます。
-
T > [Graph Solve] > [y-Cal]を選ぶ。
-
表示されるダイアログに値を入力し、Oを押す。
-
操作を終了するには、bを押す。
回帰グラフ上の、座標値が、ウインドウ下部に表示されます。
、座標がウインドウの範囲内にある場合は、グラフ上のその座標にポインターが現れます。
Oを押すとダイアログが再表示され、別の値を入力できます。
背景画像の透明度を調整するには(Fade I/O)
グラフウインドウの背景画像の透明度を調整する(Fade I/O)を参照してください。
複数のグラフ設定を使ってグラフを描く
Draw Statistics GraphメニューのGraph1、Graph2、Graph3は、それぞれグラフ設定を保存するための独立したエリアです。初期設定では、Graph2とGraph3はNone(グラフを描かない)に設定されており、Graph1の設定だけを使ってグラフが描かれます。
必要に応じて、2つまたは3つのグラフ設定を使って、複数のグラフを同時に描くことができます。
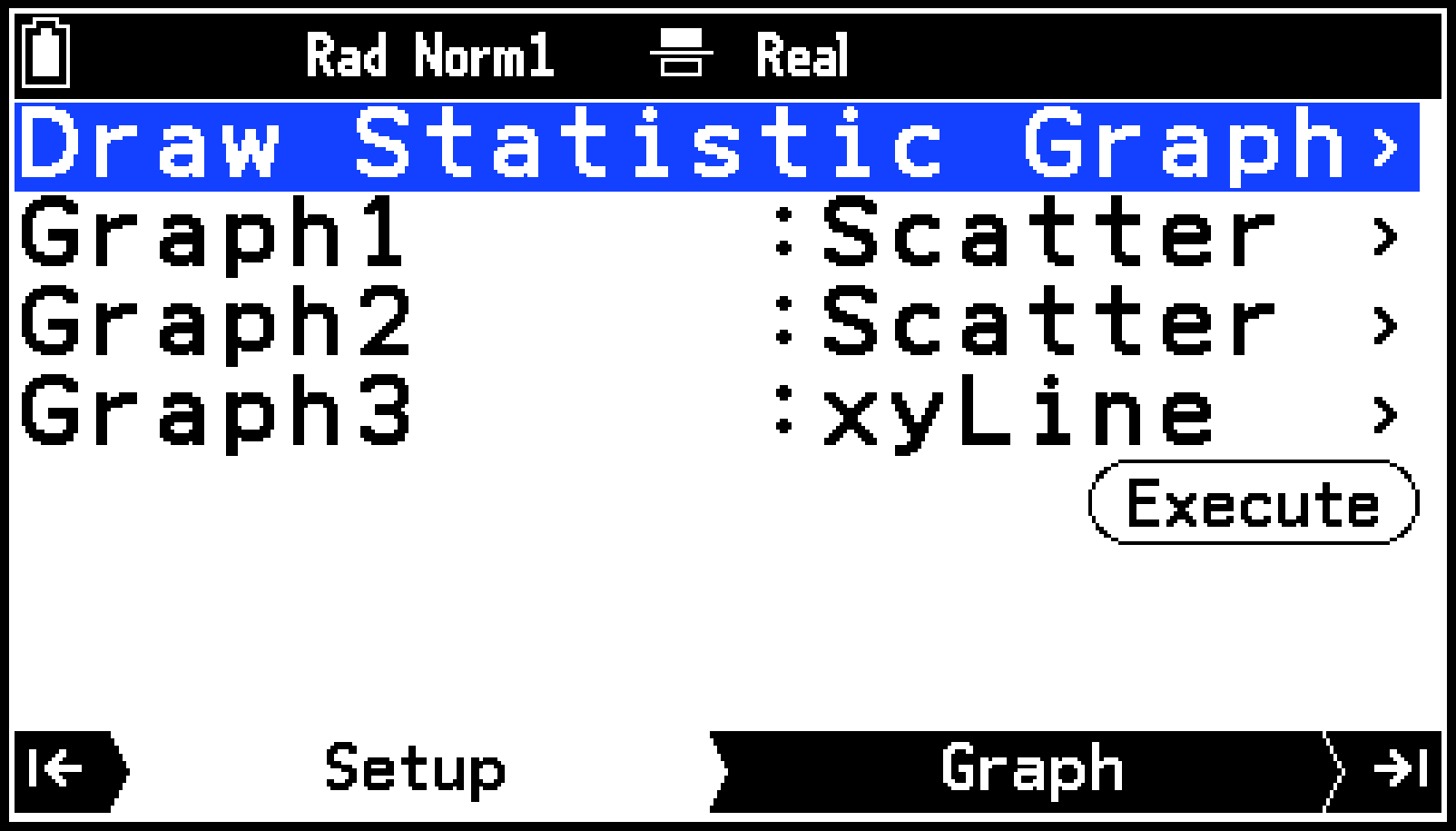
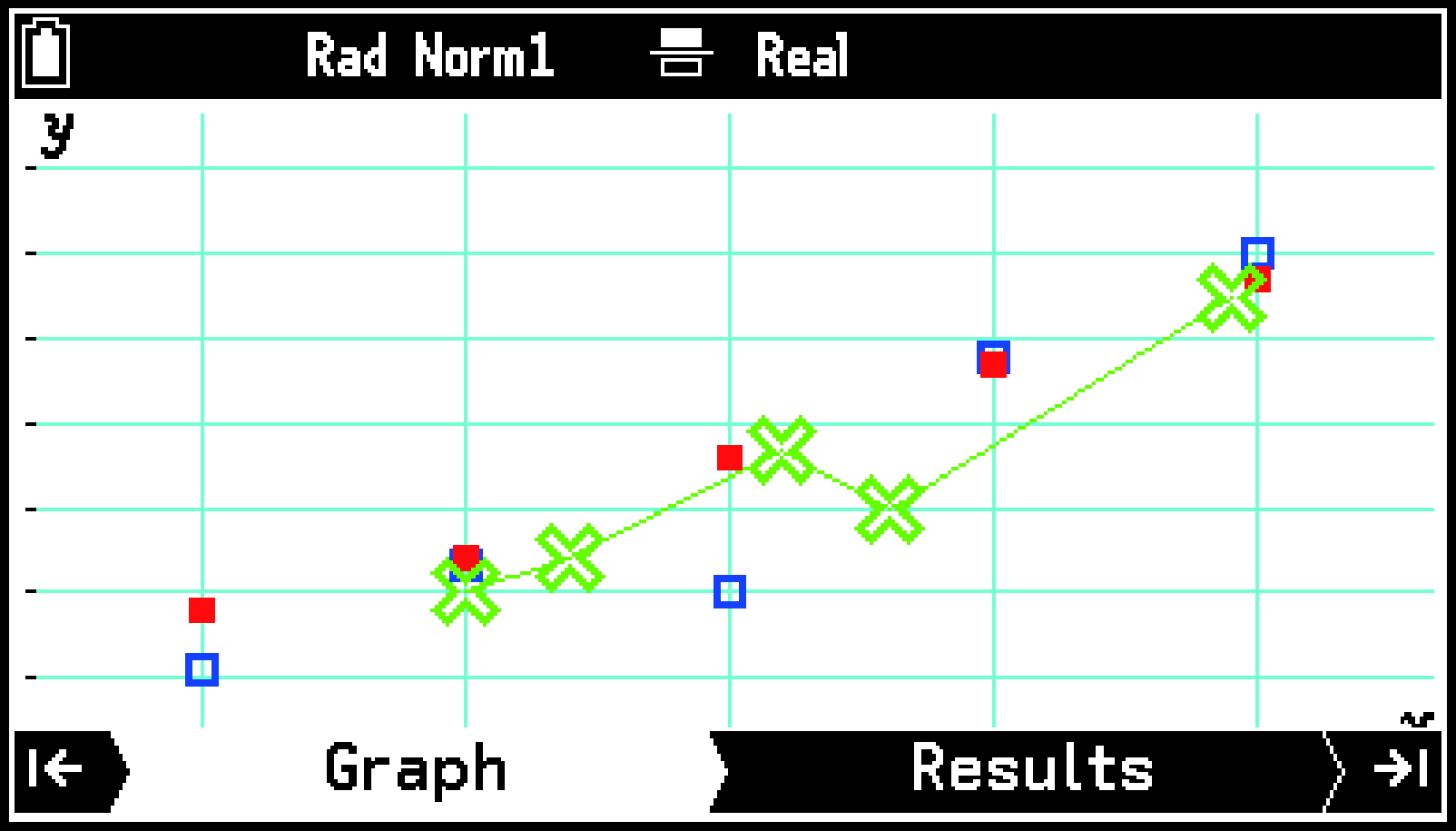
複数のグラフ設定を同時に使ってグラフを描く際は、下記の点にご注意ください。
GraphタブからResultsタブに移動するために>を押すと、どのグラフ設定を使うかを選ぶメニューが表示されます。メニューからグラフ設定を選び、Oを押してください。
1変数のグラフと2変数のグラフのグラフ設定をそれぞれ別のエリアに割り当てて、同時にグラフを描くことはできません。
円グラフを描くとき、円グラフのグラフ設定を割り当てたエリア以外のエリアは、Noneに設定してください。棒グラフも同様です。円グラフと棒グラフは、一度に1つのグラフ設定だけを使って描くことが可能です。
仮説検定を実行する
統計的な仮説をさまざまな方法で検定し、結果を数値およびグラフで表示します。
操作の流れ
-
必要に応じてList Editorにデータを入力し、リスト変数を作成する。
-
Statisticsアプリで実行したいことを選ぶに従って操作し、[Hypothesis Test](仮説検定)を選ぶ。
-
検定の種類を選ぶ。
-
Hypothesis Testメニューの2行目を反転させ、Oを押す。
-
表示されるメニューから、検定の種類を選ぶ。
-
標本データの指定方法を選ぶ。
-
[Data]を反転させ、Oを押す。
-
下表のとおりに操作する。
-
対立仮説のパラメーターを入力する。
-
[]を反転させ、Oを押す。
-
表示されるメニューで検定の方向(≠、<、または>)を反転させ、Oを押す。
-
[]を反転させ、仮定母平均の数値を入力し、Oを押す。
-
その他の各パラメーターを入力する。
-
必要に応じて、グラフの描画色を指定する。*2
-
[Color]を反転させ、Oを押す。
-
表示されるメニューで希望する色を反転させ、Oを押す。
-
>を押す。または、
を反転させOを押す。 -
グラフを表示するには、>を押す。*2
入力の操作について詳しくは、データを入力するを参照してください。
検定の種類に応じて、必要なだけリスト変数を作成します。検定の種類とリスト変数を参照してください。1次回帰の検定・カイ2乗()適合度検定・分散分析(ANOVA)を実行する場合は、リスト変数の作成が必須です。
Hypothesis Testメニューが、Setupタブに表示されます。
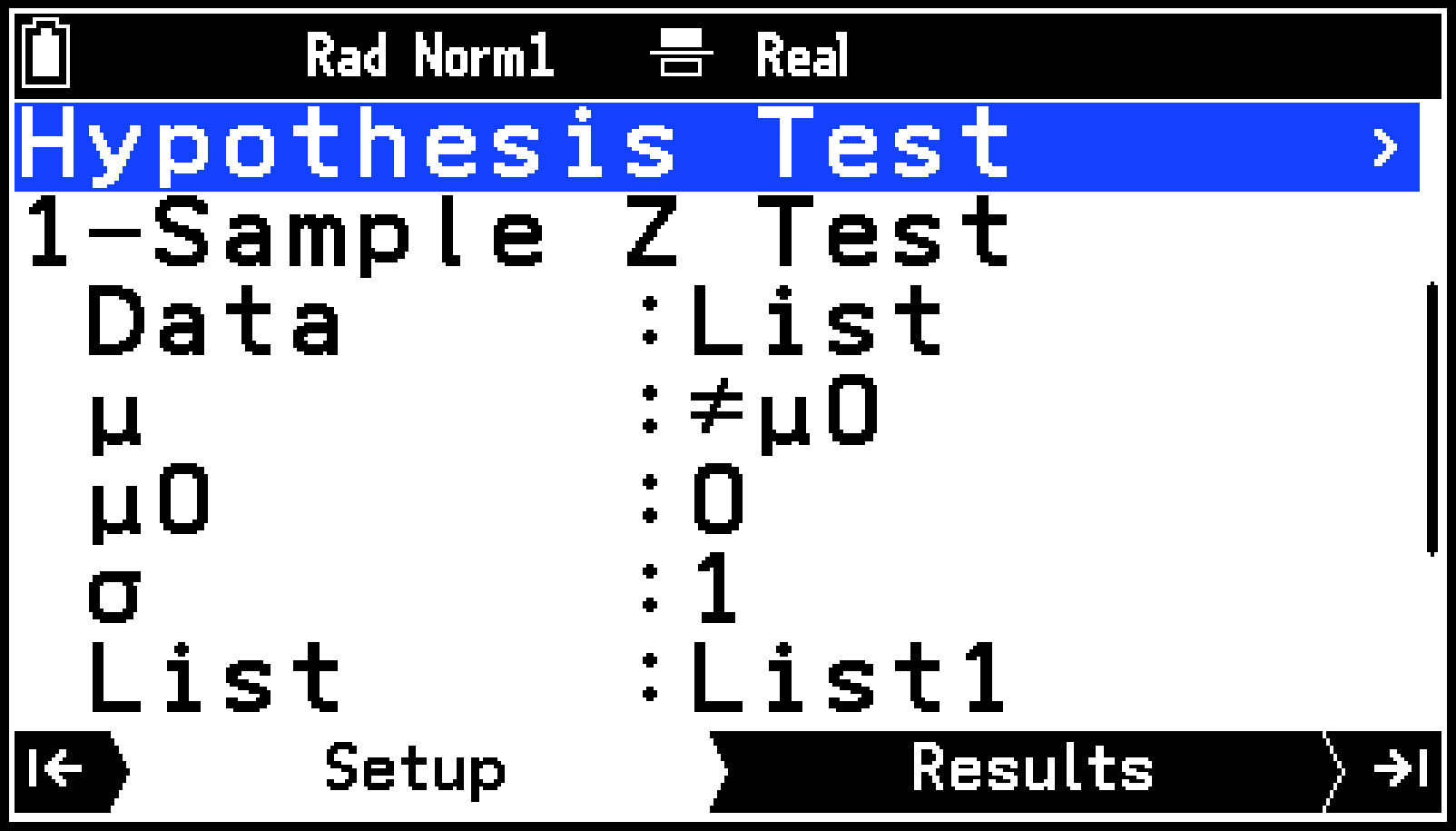
|
これを選ぶには: |
このメニュー項目を選ぶ: |
選んだら: |
|---|---|---|
|
1標本の検定 |
[Z Test] > [1-Sample Z Test] |
手順4へ |
|
2標本の検定 |
[Z Test] > [2-Sample Z Test] |
|
|
1比率の検定 |
[Z Test] > [1-Proportion Z Test] |
手順5へ |
|
2比率の検定 |
[Z Test] > [2-Proportion Z Test] |
|
|
1標本の検定 |
[t Test] > [1-Sample t Test] |
手順4へ |
|
2標本の検定 |
[t Test] > [2-Sample t Test] |
|
|
1次回帰の検定 |
[t Test] > [Linear Regression t Test] |
手順5へ |
|
カイ2乗()適合度検定 |
[ Test] > [ Goodness-of-Fit Test] |
手順6へ |
|
カイ2乗()独立性検定 |
[ Test] > [ Two-Way Test] |
|
|
2標本の検定 |
[2-Sample F Test] |
手順4へ |
|
分散分析(ANOVA) |
[ANOVA] |
手順6へ |
|
これをするには: |
このように操作する: |
|---|---|
|
標本データをリスト変数で指定する |
表示されるメニューで[List]を反転させ、Oを押す。 |
|
標本の平均値・標準偏差*1・データ個数を入力する |
表示されるメニューで[Variable]を反転させ、Oを押す。 |
検定では入力不要
検定の種類に応じたパラメーターについては、検定の種類とパラメーターを参照してください。
例えば手順3で[Z Test] > [1-Sample Z Test]を選んだ場合は、下記のように操作します。
検定の種類に応じたパラメーターについては、検定の種類とパラメーターを参照してください。
検定の計算結果と入力値(または指定データから計算された要約統計量)が、Resultsタブに一覧表示されます。
表示される計算結果や、Resultsタブでできる操作については、検定のResultsタブを使うを参照してください。
Graphタブでできる操作については、検定のGraphタブを使うを参照してください。
下記の場合、この操作は不要です。
検定の種類として1次回帰の検定を選んだ場合
検定の種類として分散分析(ANOVA)を選び、[How Many] > [1]を指定した場合
検定の種類とリスト変数
実行したい検定の種類に応じてList Editorにデータを入力し、下記のリスト変数を作成します。
1次回帰の検定
|
作成が必要なリスト変数: |
Setupタブの表示: |
|---|---|
|
XList(データ)・YList(データ)・Freq(度数データ)に割り当てる、3つのリスト変数* |
 |
度数データを使わない場合は、Freqへのリスト変数の割り当ては不要です。
カイ2乗()適合度検定
|
作成が必要なリスト変数: |
Setupタブの表示: |
|---|---|
|
Observed(観測値)*・Expected(期待度数)に割り当てる、2つのリスト変数 |
 |
どのリスト要素も正の整数
分散分析(ANOVA)
One-Way ANOVA(一元配置分散分析)またはTwo-Way ANOVA(二元配置分散分析)のどちらかを選んで実行します。Setupタブで[How Many] > [1]を選ぶとOne-Way ANOVA、[2]を選ぶとTwo-Way ANOVAとなります。
|
分散分析の種類: |
作成が必要なリスト変数: |
Setupタブの表示: |
|---|---|---|
|
One-Way ANOVA |
Factor A(因子Aの条件)・Dependnt(標本データ)に割り当てる、2つのリスト変数 |
 |
|
Two-Way ANOVA |
Factor A(因子Aの条件)・Factor B(因子Bの条件)・Dependnt(標本データ)に割り当てる、3つのリスト変数 |
 |
分散分析で使用するリスト変数は、下記の要領で作成します。
One-Way ANOVA: 例えば因子Aの条件が2通り(条件1・条件2)ある場合、下記のように各リストを作成します。
|
Factor A |
Dependent |
|
|
|---|---|---|---|
|
1 |
113 |
 |
条件1の標本データ |
|
1 |
116 |
||
|
2 |
133 |
|
条件2の標本データ |
|
2 |
131 |
Two-Way ANOVA: 例えば因子Aと因子Bの条件がそれぞれ2通り(条件1・条件2)ある場合、下記のように各リストを作成します。
|
Factor A |
Factor B |
Dependent |
|
|
|---|---|---|---|---|
|
1 |
1 |
113 |
|
因子A条件1×因子B条件1の標本データ |
|
1 |
1 |
116 |
||
|
2 |
1 |
133 |
|
因子A条件2×因子B条件1の標本データ |
|
2 |
1 |
131 |
||
|
1 |
2 |
139 |
|
因子A条件1×因子B条件2の標本データ |
|
1 |
2 |
132 |
||
|
2 |
2 |
126 |
|
因子A条件2×因子B条件2の標本データ |
|
2 |
2 |
122 |
1標本または2標本の 検定・1標本または2標本の検定・2標本の検定
操作の流れの手順4で[Data] > [List]を選んだ場合に、下記のリスト変数を作成することが必要となります。
|
標本データ: |
作成が必要なリスト変数: |
Setupタブの表示: |
|---|---|---|
|
1標本データ(度数なし) |
Listに割り当てるリスト変数 |
 |
|
1標本データ(度数付き) |
List・Freqに割り当てる、2つのリスト変数 |
|
|
2標本データ(度数なし) |
List(1)・List(2)に割り当てる、2つのリスト変数 |
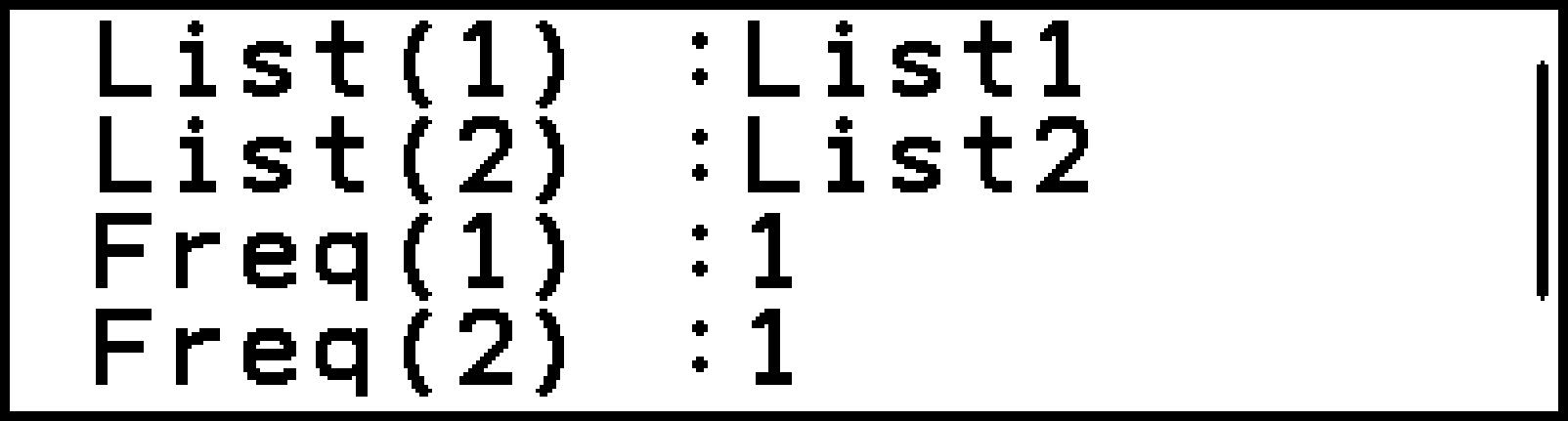 |
|
2標本データ(度数付き) |
List(1)・List(2)・Freq(1)・Freq(2)に割り当てる、4つのリスト変数 |
検定の種類とパラメーター
対立仮説のパラメーター
|
検定の種類: |
パラメーター: |
|---|---|
|
1標本の検定 |
: 検定条件(“≠”は両側検定、“<”は下片側検定、“>”は上片側検定を指定) |
|
2標本の検定 |
: 検定条件(“≠”は両側検定、“<”は標本1が標本2より小さい場合の片側検定、“>”は標本1が標本2より大きい場合の片側検定を指定) |
|
1比率の検定 |
Prop: 検定条件(“≠”は両側検定、“<”は下片側検定、“>”は上片側検定を指定) |
|
2比率の検定 |
: 検定条件(“≠”は両側検定、“<”は標本1が標本2より小さい場合の片側検定、“>”は標本1が標本2より大きい場合の片側検定を指定) |
|
1次回帰の検定 |
&: 検定条件(“≠0”は両側検定、“< 0”は下片側検定、“> 0”は上片側検定を指定) |
|
2標本の検定 |
: 検定条件(“≠”は両側検定、“<”は標本1が標本2より小さい場合の片側検定、“>”は標本1が標本2より大きい場合の片側検定を指定) |
その他のパラメーター
下表中のアスタリスク(*)付きのパラメーターは、操作の流れの手順4で[Data] > [Variable]を選んだ場合に入力が必要です。
|
検定の種類: |
パラメーター: |
|---|---|
|
1標本の検定 |
: 母標準偏差( > 0) : 標本の平均値* : 標本のデータの個数(正の整数)* |
|
2標本の検定 |
: 標本1の母標準偏差( > 0) : 標本2の母標準偏差( > 0) : 標本1の平均値* : 標本1のデータの個数(正の整数)* : 標本2の平均値* : 標本2のデータの個数(正の整数)* |
|
1比率の検定 |
: 標本値( ≥ 0 の整数) : 標本のデータの個数(正の整数) |
|
2比率の検定 |
: 標本1のデータ値( ≥ 0 の整数) : 標本1のデータの個数(正の整数) : 標本2のデータ値( ≥ 0 の整数) : 標本2のデータの個数(正の整数) |
|
1標本の検定 |
: 標本の平均値* : 標本標準偏差( > 0)* : 標本のデータの個数(正の整数)* |
|
2標本の検定 |
: 標本1の平均値* : 標本1の標本標準偏差( > 0)* : 標本1のデータの個数(正の整数)* : 標本2の平均値* : 標本2の標本標準偏差( > 0)* : 標本2のデータの個数(正の整数)* Pooled: プールする(On)またはプールしない(Off) |
|
カイ2乗()適合度検定 |
Observed: 観測値が格納されているリスト変数(List 1~26)を指定します(どのリスト要素も正の整数であること)。 Expected: 期待度数の保存先となるリスト変数(List 1~26)を指定します。 df: 自由度(正の整数) CNTRB: 計算結果として得られた、各度数の寄与(contribution)の保存先となるリスト変数(List 1~26)を指定します。 |
|
カイ2乗()独立性検定 |
Observed: 観測値が格納されている行列変数(Mat A~Z)を指定します。必ず下記の条件を満たす行列を指定してください。条件を満たしていない行列を指定すると、エラーとなります。 2行2列以上の行列であること。 行列のすべての要素が、正の整数であること。 Expected: 期待度数が格納されている行列変数(Mat A~Z)を指定します。 |
|
2標本の検定 |
: 標本1の標本標準偏差( > 0)* : 標本1のデータの個数(正の整数)* : 標本2の標本標準偏差( > 0)* : 標本2のデータの個数(正の整数)* |
|
分散分析(ANOVA) |
How Many: 1: One-Way ANOVA(一元配置分散分析) 2: Two-Way ANOVA(二元配置分散分析) |
検定のResultsタブを使う
Resultsタブに表示される情報
ANOVA以外の検定を実行したとき
検定の計算結果と標本データの要約統計量が、Resultsタブに表示されます。表示される各項目の意味は、下記のとおりです。
検定の計算結果
|
: |
値 |
|
: |
値(検定) |
|
: |
値(検定) |
|
: |
値(検定) |
|
: |
値(検定) |
|
: |
期待標本比率(1比率、2比率の検定) |
|
: |
標本1の期待比率(2比率の検定) |
|
: |
標本2の期待比率(2比率の検定) |
|
df: |
自由度(2標本の検定、1次回帰の検定、検定) |
|
: |
定数項(1次回帰の検定) |
|
: |
係数(1次回帰の検定) |
標本データの要約統計量
|
: |
標本の平均値 |
|
: |
標本1の平均値 |
|
: |
標本2の平均値 |
|
: |
標本標準偏差 |
|
: |
標本1の標準偏差 |
|
: |
標本2の標準偏差 |
|
: |
標本pの標準偏差 |
|
: |
標本データの個数 |
|
: |
標本1のデータの個数 |
|
: |
標本2のデータの個数 |
|
: |
標準誤差 |
|
: |
相関係数 |
|
: |
決定係数 |
ANOVAを実行したとき
計算結果が、教科書等で示されているのと同じテーブル形式で表示されます。
一元配置分散分析(One-Way ANOVA)

1行目: 因子Aの値
2行目: ERRの値
二元配置分散分析(Two-Way ANOVA)
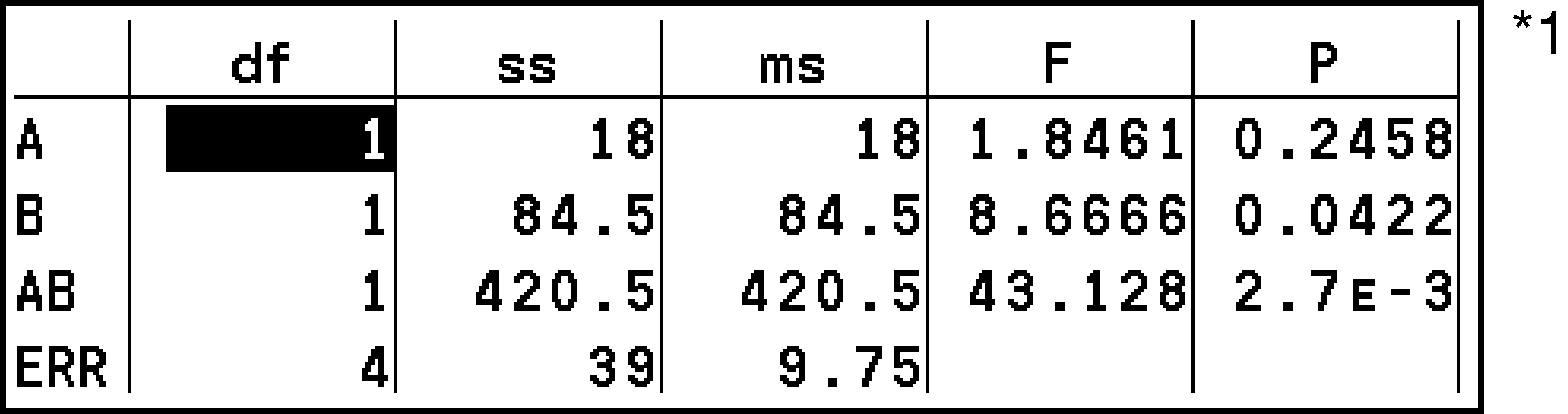
1行目: 因子Aの値
2行目: 因子Bの値
3行目: 因子A × 因子Bの値*2
4行目: ERRの値
この表は本機では2画面にまたがって表示されるので、すべての内容を見るには、左右にスクロールする必要があります。
繰り返しのない条件での演算では、この行は表示されません。
1列目: df ... 自由度
2列目: ss ... 平方和
3列目: ms ... 平均平方
4列目: F ... 値
5列目: P ... 値
参考
Resultsタブに表示される値は、C > [Variable Data] > [Statistics] > [Result] > [Test]およびC > [Variable Data] > [Statistics] > [Input]に含まれる変数に格納されます。 ただし変数とは、C > [Variable Data] > [Statistics] > [Graph]に含まれます。
計算結果の表示中にできること
下記の操作で、Resultsタブに表示中のすべての数値*1を、リスト変数に保存します。
-
T > [Save Result in List]を選ぶ。
-
表示されるダイアログに保存先のリスト番号*2*3を入力し、Oを押す。
表示中の計算結果と入力値を含みます。ただし、対立仮説のパラメーターは保存されません。
内容が空のリスト番号を入力してください。上書き保存はできません。
分散分析(ANOVA)の場合、5列ある計算結果の各列が、入力したリスト番号を始点とした5つのリスト変数に保存されます。このため、指定できるリスト番号は1~22の範囲です。
参考
1次回帰の検定の計算結果を表示しているときは、下記のことができます。
計算結果の回帰式をファンクション変数に保存する
実際のデータと回帰モデルによる計算値の残差を求め、リスト変数に保存する
操作のしかたは、回帰モデル情報の表示中にできることを参照してください。
検定のGraphタブを使う
Two-Way ANOVA(二元配置分散分析)以外の検定を実行したとき
1標本または2標本の検定・1比率または2比率の検定・1標本または2標本の検定・カイ2乗()適合度検定・カイ2乗()独立性検定・2標本の検定を実行したときのGraphタブでは、下記のことができます。
|
これをするには: |
このメニュー項目を選ぶ: |
|---|---|
|
値を表示する |
T > [Calculate P Value] |
|
検定: 値を表示し、グラフ上の該当する点に十字ポインターを表示する |
T > [Calculate Z Value]*1*2 |
|
1標本または2標本の検定: 値を表示し、グラフ上の該当する点に十字ポインターを表示する |
T > [Calculate T Value]*1*2 |
|
カイ2乗()検定: 値を表示し、グラフ上の該当する点に十字ポインターを表示する |
T > [Calculate CHI Value]*1*2 |
|
2標本の検定: 値を表示し、グラフ上の該当する点に十字ポインターを表示する |
T > [Calculate F Value]*1*2 |
両側検定の場合、lまたはrを押すたびに、2つの値の間で十字ポインターが移動します。
該当する点がディスプレイの範囲外の場合は、表示されません。
参考
上記の操作で表示される計算結果は、下記のアルファ変数に保存されます。
|
検定 |
変数ZとPそれぞれに、値と値が保存されます。 |
|
検定 |
変数TとPそれぞれに、値と値が保存されます。 |
|
検定 |
変数CとPそれぞれに、値と値が保存されます。 |
|
検定 |
変数FとPそれぞれに、値と値が保存されます。 |
下記は、1標本の検定を≠(両側検定)で実行し、グラフを描いたときの表示例です。 右下は、T > [Calculate T Value]を選んだときの表示例です。
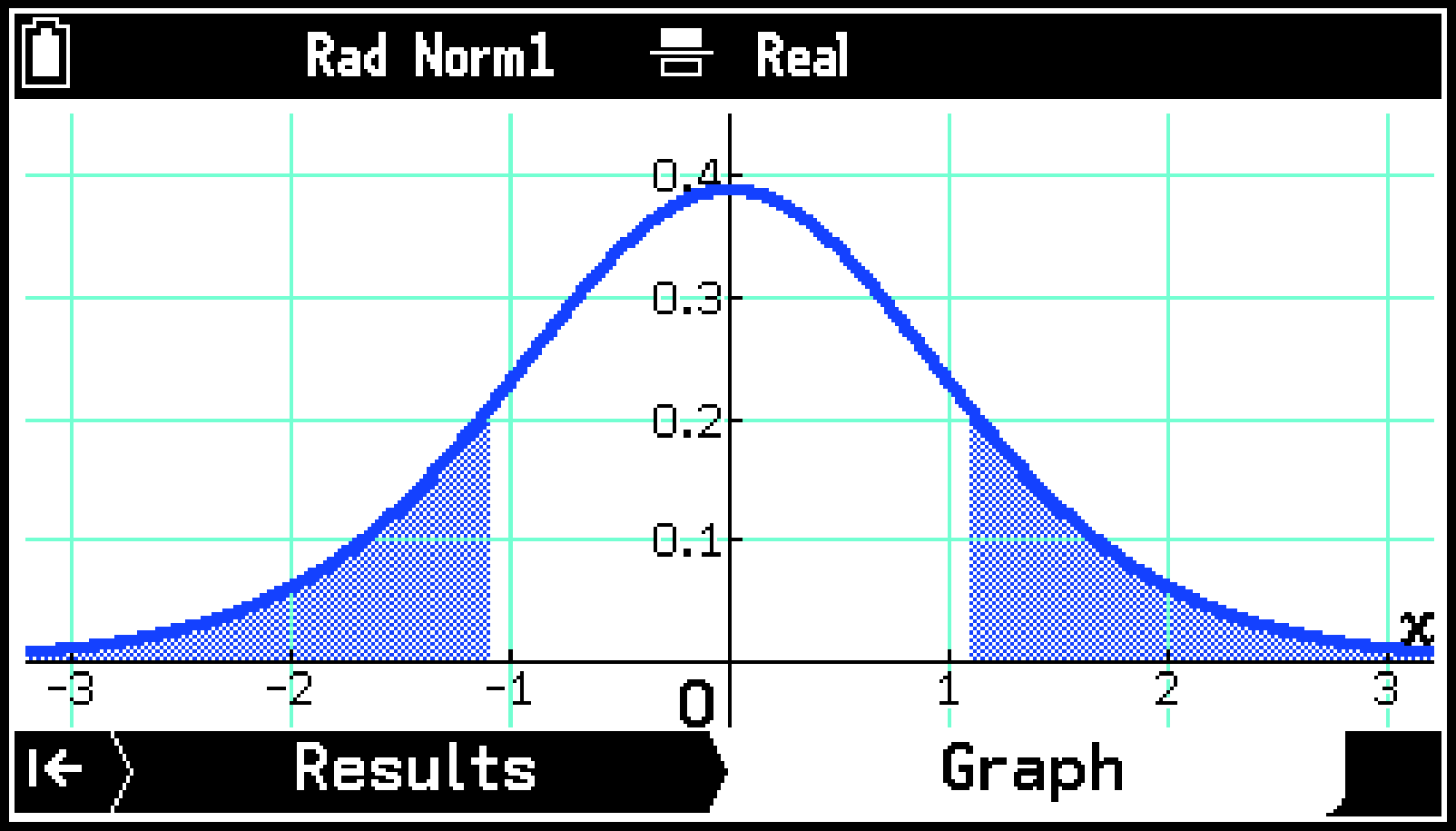
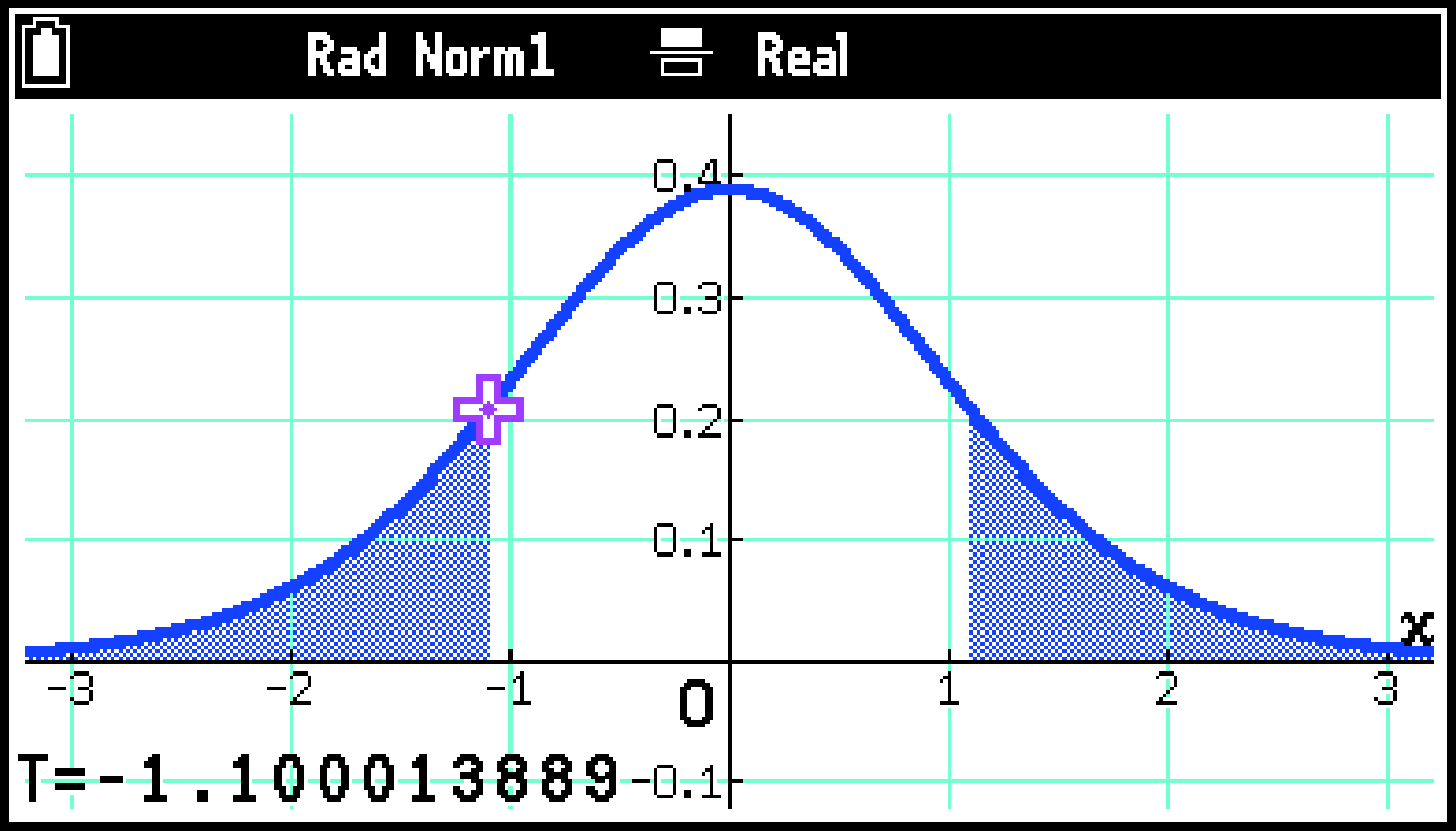
Two-Way ANOVA(二元配置分散分析)を実行したとき
交互作用グラフの描画が可能です。グラフの本数は因子B、軸のデータは因子Aに基づいて決まります。軸のデータは、カテゴリー(因子Aと因子Bの条件組み合わせ)ごとの平均値です。
T > [Trace]を選ぶとグラフ上に十字ポインターが表示されます。lまたはr押すと、ポインターがグラフ上を移動します。 複数のグラフが描かれている場合は、dまたはuを押すと、ポインターがグラフ間を移動します。
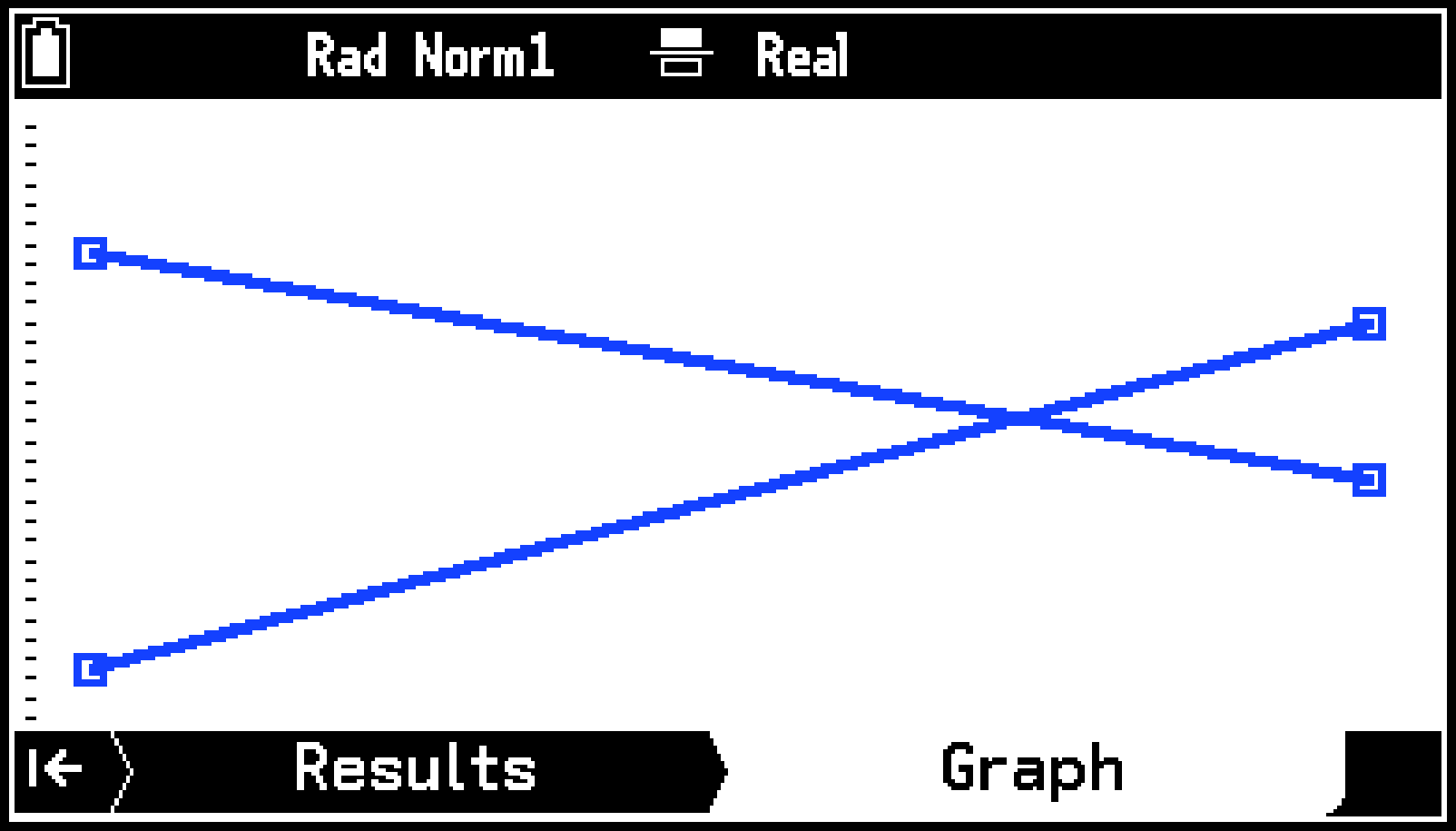
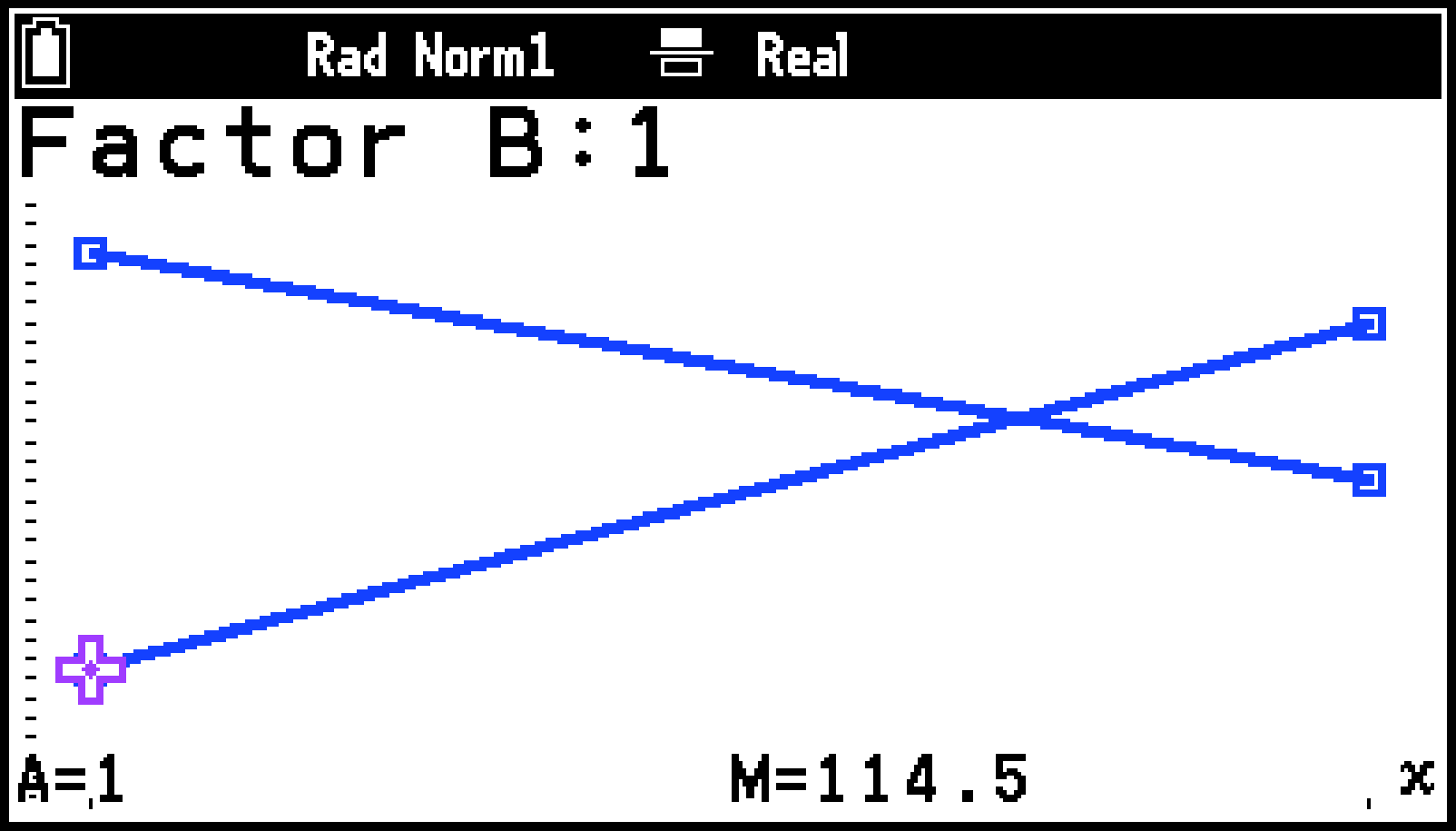
トレースを実行すると、変数Aに因子Aの最後の条件番号、変数Mに最後のカテゴリーの平均値が、それぞれ保存されます。
信頼区間を求める
与えられた標本データと信頼水準から、信頼区間の上限と下限を求めます。
操作の流れ
-
必要に応じてList Editorにデータを入力し、リスト変数を作成する。
-
Statisticsアプリで実行したいことを選ぶに従って操作し、[Confidence Interval](信頼区間)を選ぶ。
-
信頼区間の種類を選ぶ。
-
Confidence Intervalメニューの2行目を反転させ、Oを押す。
-
表示されるメニューから、信頼区間の種類を選ぶ。
-
標本データの指定方法を選ぶ。
-
[Data]を反転させ、Oを押す。
-
下表のとおりに操作する。
-
パラメーターを入力する。
-
[C-Level]を反転させ、数字キーを使って信頼水準を入力する。
-
Oを押します。
-
その他の各パラメーターを入力する。
-
>を押す。または、
を反転させOを押す。
入力の操作について詳しくは、データを入力するを参照してください。
作成するリスト変数については、信頼区間の種類とリスト変数を参照してください。
Confidence Intervalメニューが、Setupタブに表示されます。
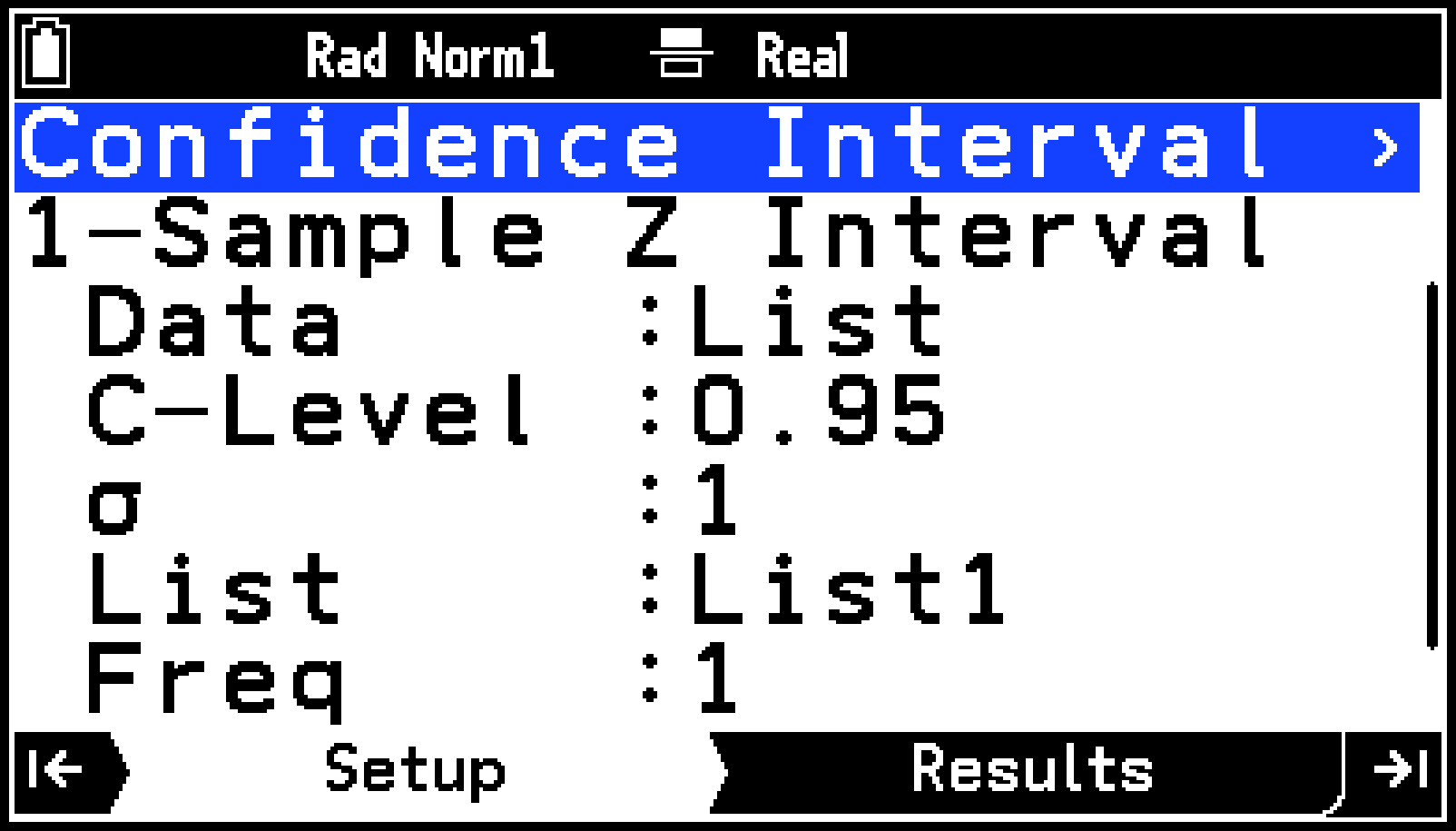
|
これを選ぶには: |
このメニュー項目を選ぶ: |
選んだら: |
|---|---|---|
|
1標本の信頼区間 |
[Z Confidence Interval] > [1-Sample Z Interval] |
手順4へ |
|
2標本の信頼区間 |
[Z Confidence Interval] > [2-Sample Z Interval] |
|
|
1比率の信頼区間 |
[Z Confidence Interval] > [1-Proportion Z Interval] |
手順5へ |
|
2比率の信頼区間 |
[Z Confidence Interval] > [2-Proportion Z Interval] |
|
|
1標本の信頼区間 |
[t Confidence Interval] > [1-Sample t Interval] |
手順4へ |
|
2標本の信頼区間 |
[t Confidence Interval] > [2-Sample t Interval] |
|
これをするには: |
このように操作する: |
|---|---|
|
標本データをリスト変数で指定する |
表示されるメニューで[List]を反転させ、Oを押す。 |
|
標本の平均値、標準偏差、およびデータ個数を入力する |
表示されるメニューで[Variable]を反転させ、Oを押す。 |
0以上1未満の数値を入力します。よく使われる信頼水準は、0.95(95%)と0.99(99%)です。
信頼区間の種類とパラメーターを参照してください。
信頼区間の計算結果と標本データの要約統計量が、Resultsタブに表示されます。表示される各項目の意味は、下記のとおりです。
信頼区間の計算結果
|
Lower: |
信頼区間の下限 |
|
Upper: |
信頼区間の上限 |
|
df: |
自由度 |
|
: |
標本の期待比率 |
|
: |
標本1の期待比率 |
|
: |
標本2の期待比率 |
標本データの要約統計量
|
: |
標本の平均値 |
|
: |
標本1の平均値 |
|
: |
標本2の平均値 |
|
: |
標本標準偏差 |
|
: |
標本1の標準偏差 |
|
: |
標本2の標準偏差 |
|
: |
標本pの標準偏差 |
|
: |
標本データの個数 |
|
: |
標本1のデータの個数 |
|
: |
標本2のデータの個数 |
参考
Resultsタブに表示中の値を、下記操作でリストに保存できます。
-
T > [Save Result in List]を選ぶ。
-
表示されるダイアログに保存先のリスト番号*を入力し、Oを押す。
内容が空のリスト番号を入力してください。上書き保存はできません。
Resultsタブに表示される値は、それぞれ下記メニュー項目に含まれる変数に格納されます。
信頼区間の計算結果: C > [Variable Data] > [Statistics] > [Result] > [Confidence Interval]
標本データの要約統計量: C > [Variable Data] > [Statistics] > [Input]
信頼区間の種類とリスト変数
標本データのリストを使って信頼区間を求める場合、信頼区間の種類に応じて下記のリスト変数を作成します。
|
標本データ: |
作成するリスト変数:: |
Setupタブの表示: |
|---|---|---|
|
1標本データ(度数なし) |
Listに割り当てるリスト変数 |
 |
|
1標本データ(度数付き) |
List・Freqに割り当てる、2つのリスト変数 |
|
|
2標本データ(度数なし) |
List(1)・List(2)に割り当てる、2つのリスト変数 |
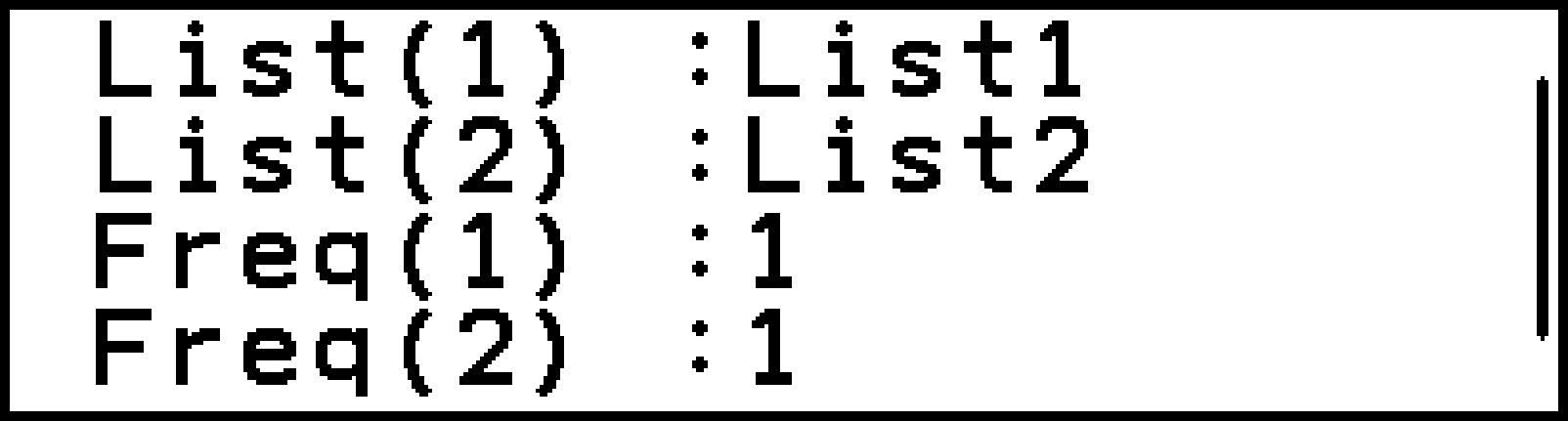 |
|
2標本データ(度数付き) |
List(1)・List(2)・Freq(1)・Freq(2)に割り当てる、4つのリスト変数 |
信頼区間の種類とパラメーター
下表中のアスタリスク(*)付きのパラメーターは、操作の流れの手順4で[Data] > [Variable]を選んだ場合に入力が必要です。
|
信頼区間の種類: |
パラメーター: |
|---|---|
|
1標本の信頼区間 |
: 母標準偏差( > 0) : 標本の平均値* : 標本のデータの個数(正の整数)* |
|
2標本の信頼区間 |
: 標本1の母標準偏差( > 0) : 標本2の母標準偏差( > 0) : 標本1の平均値* : 標本1のデータの個数(正の整数)* : 標本2の平均値* : 標本2のデータの個数(正の整数)* |
|
1比率の信頼区間 |
: 標本値( ≥ 0 の整数) : 標本のデータの個数(正の整数) |
|
2比率の信頼区間 |
: 標本1のデータ値( ≥ 0 の整数) : 標本1のデータの個数(正の整数) : 標本2のデータ値( ≥ 0 の整数) : 標本2のデータの個数(正の整数) |
|
1標本の信頼区間 |
: 標本の平均値* : 標本標準偏差( > 0)* : 標本のデータの個数(正の整数)* |
|
2標本の信頼区間 |
: 標本1の平均値* : 標本1の標本標準偏差( > 0)* : 標本1のデータの個数(正の整数)* : 標本2の平均値* : 標本2の標本標準偏差( > 0)* : 標本2のデータの個数(正の整数)* Pooled: プールする(On)またはプールしない(Off) |
統計グラフの表示範囲設定について(View Window)
統計グラフのView Window(ビューウインドウ)は、グラフに応じて自動的に設定されます。これは、本機の初期設定でS > [View Window] > [Auto]が選ばれているためです。
S > [View Window] > [Manual]に切り替えると、グラフウインドウでT > [View Window]を選ぶと表示されるメニューを使ったView Window設定の変更が、グラフウインドウの表示範囲に適用されるようになります。
View Windowの設定について詳しくは、グラフウインドウの表示範囲を指定する(View Window)を参照してください。
参考
下記のグラフでは、S > [View Window]の設定にかかわらず、自動的に表示範囲が設定されます。
円グラフ・1標本の検定・2標本の検定・1比率の検定・2比率の検定・1標本の検定・2標本の検定・カイ2乗()適合度検定・カイ2乗()独立性検定・2標本の検定(軸方向のみ無視)